
Зачем нужны функции Обратного вызова
Вы часто будет слышать, что JavaScrip является однопоточным. Это означает, что он может делать одну вещь за раз. При выполнении медленной операции, такой как получение данных из удалённого API, это может быть проблематичным. Было бы не очень приятно, если бы ваша программа зависла до тех пор, пока данные не будут возвращены.
Один из способов, которым JavaScript позволяет избежать этого узкого места, — использование обратного вызова. Мы можем передать вторую функцию в качестве аргумента функции, отвечающей за выборку данных. Затем запускается запрос на получение данных, но вместо ожидания интерпретатор JavaScript продолжает выполнение остальной части программы. Когда приходит ответ от API, функция обратного вызова выполняется и может выполнять действия с результатом:
JavaScript — язык, управляемый событиями
Вы также услышите, как люди говорят, что JavaScript — язык управляемый событиями (event-driven language). Это означает, что он может прослушивать события и не реагировать на них, продолжая выполнять дальнейший код и не блокируя свой единственный поток.
И как он это делает? Вы уже догадались: обратные вызовы.
Представьте, что ваша программа привязывает слушатель событий к кнопке, а затем сидит и ждёт, пока кто-нибудь не нажмёт эту кнопку, отказываясь делать что-либо ещё. Это было бы не круто!
Используя обратные вызовы, мы можем указать, что определённый блок кода должен запускаться в ответ на определённое событие:
В приведённом выше примере функция представляет собой обратный вызов выполняющийся в ответ на действие происходящее на веб-странице (клик по кнопке).
Используя этот подход, мы можем реагировать на столько событий, сколько захотим, оставляя интерпретатору JavaScript свободу делать всё, что ему нужно.
Функции первого класса и высшего порядка
Ещё пара модных словечек с которыми вы можете столкнуться при изучении обратных вызовов, — это функции первого класса
и функции высшего порядка
. Звучит пугающе, но это не так.
Когда мы говорим, чт JavaScript поддерживает функции первого класса, это означает, что мы можем обращать с функциями как с обычными значениями. Мы можем хранить их в переменной. Мы можем возвращать их из другой функции. И как мы уже видели, мы можем передавать их как аргументы.
Что касается функций высшего порядка, то это просто функции, которые либо принимают функцию в качестве аргумента, либо возвращают функцию в качестве результата. Есть несколько нативных функций JavaScript являющихся функциями высшего порядка, например . Давайте используем её для демонстрации создания и запуска обратного вызова.
Несколько слов о наступающем будущем — HTTP/2
Первая версия протокола HTTP была принята 20 лет назад. После этого 10 лет была тишина, пока Google не стал разрабатывать свой протокол SPDY поверх HTTP, что дало ускорение работе над HTTP/2. После серёзных подвижек Google отказался от разработки SPDY в пользу HTTP/2.
Вторая версия протокола отличается от первой чуть меньше, чем полностью.
- Протокол уже стал бинарен, а значит человеко нечитаемый.
- Несмотря на возможность работать без шифрования, все современные браузеры будут поддерживать именно вариант с шифрованием.
- В протоколе предусмотрена возможность push-сообщений, инициированных сервером.
- Протокол позволяет мультиплексирование — отправку нескольких запросов внутри одного соединения.
- Умеет сжимать данные заголовков.
Новый протокол безопаснее и в несколько раз быстрее. Самое приятное, что последние версии современных браузеров понимают http2, и половина наиболее крупных и популярных сайтов уже готовы к переходу на него. С приходом http2 веб станет ещё более интерактивным, а приложения приблизятся к десктопным.
Поиск совпадений: метод exec
Метод возвращает массив и ставит свойства регулярного выражения.
Если совпадений нет, то возвращается null.
Например,
// Найти одну d, за которой следует 1 или более b, за которыми одна d
// Запомнить найденные b и следующую за ними d
// Регистронезависимый поиск
var myRe = /d(b+)(d)/ig;
var myArray = myRe.exec("cdbBdbsbz");
В результате выполнения скрипта будут такие результаты:
| Объект | Свойство/Индекс | Описания | Пример |
| Содержимое . | |||
| Индекс совпадения (от 0) | |||
| Исходная строка. | |||
| Последние совпавшие символы | |||
| Совпадения во вложенных скобках, если есть. Число вложенных скобок не ограничено. | |||
| Индекс, с которого начинать следующий поиск. | |||
| Показывает, что был включен регистронезависимый поиск, флаг «». | |||
| Показывает, что был включен флаг «» поиска совпадений. | |||
| Показывает, был ли включен флаг многострочного поиска «». | |||
| Текст паттерна. |
Если в регулярном выражении включен флаг «», Вы можете вызывать метод много раз для поиска последовательных совпадений в той же строке. Когда Вы это делаете, поиск начинается на подстроке , с индекса . Например, вот такой скрипт:
var myRe = /ab*/g;
var str = "abbcdefabh";
while ((myArray = myRe.exec(str)) != null) {
var msg = "Found " + myArray + ". ";
msg += "Next match starts at " + myRe.lastIndex;
print(msg);
}
Этот скрипт выведет следующий текст:
Found abb. Next match starts at 3 Found ab. Next match starts at 9
В следующем примере функция выполняет поиск по input. Затем делается цикл по массиву, чтобы посмотреть, есть ли другие имена.
Предполагается, что все зарегистрированные имена находятся в массиве А:
var A = ;
function lookup(input)
{
var firstName = /\w+/i.exec(input);
if (!firstName)
{
print(input + " isn't a name!");
return;
}
var count = 0;
for (var i = 0; i < A.length; i++)
{
if (firstName.toLowerCase() == A.toLowerCase())
count++;
}
var midstring = (count == 1) ? " other has " : " others have ";
print("Thanks, " + count + midstring + "the same name!")
}
Обрабатываем больше экшенов¶
У нас есть еще два экшена, которые должны быть обработаны! Так же, как мы сделали с мы имортируем и экшены и затем допишем наш редьюсер для обработки .
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
Как и раньше, мы никогда не изменяем непосредственно или его поля. Вместо этого мы возвращаем новый объект. Новый равен старому , в конец которого добавлен новый элемент . Свежий todo был создан с использованием информации, полученной из .
Ну и наконец, имплементация обработчика для экшена не должна стать для Вас большим сюрпризом:
1 2 3 4 5 6 7 8 9 10 11 |
Поскольку мы хотим обновить конкретный элемент в массиве, не прибегая к мутациям, мы должны создать новый массив с теми же элементами, за исключением элемента по индексу. Если вы часто пишете такие операции, рекомендуется использовать хэлперы, такие как immutability-helper, updeep или даже такую библиотеку, как Immutable, которая имеет встроенную поддержку для глубоких обновлений. Просто запомните, что нельзя присваивать ничего внутри , пока вы его не склонировали.
Вложенные области видимости
Чтение переменной внутри функции. Ищем имя:
- в локальной области видимости функции;
- в локальных областях видимости объемлющих функций изнутри наружу;
- в глобальной области видимости модуля;
- в builtins (встроенная область видимости).
внутри функции:
- создает или изменяет имя х в текущей локальной области видимости функции;
- если был , то = создает или изменяет имя в ближайшей области видимости объемлющей функции.
- если был , то = создает или изменяет имя в области видимости объемлющего модуля.
Ищем в объемлющих областях, даже если объемлющая функция фактически уже вернула управление:
Функция f2 помнит переменную Х в области видимости объемлющей функции f1, которая уже неактивна.
Замыкание (фабричная функция)
Объект функции, который сохраняет свое значение в объемлющей области видимости, даже когда эти области перестали существовать.
(Для сохранения состояний лучше использовать классы).
Например, фабричные функции иногда используются в программах, когда необходимо создавать обработчики событий прямо в процессе выполнения, в соответствии со сложившимися условиями (например, когда желательно запретить пользователю вводить данные).
Определим внешнюю фукнцию, которая создает и возвращает внутреннюю функцию, не вызывая ее.
Вызовем внешнюю функцию. Она возвращает ссылку на созданную ею вложенную функцию, созданную при выполнении вложенной инструкции def:
Вызовем по этой ссылке функцию (внутреннюю!):
Вложенная функция продолжает хранить число 2, значение переменной N в функции maker даже при том, что к моменту вызова функции action функция maker уже завершила свою работу и вернула управление. В действительности имя N из объемлющей локальной области видимости сохраняется как информация о состоянии, присоединенная к функции action, и мы получаем обратно значение аргумента, возведенное в квадрат.
Теперь, если снова вызвать внешнюю функцию, мы получим новую вложенную функцию уже с другой информацией о состоянии, присоединенной к ней, — в результате вместо квадрата будет вычисляться куб аргумента, но ранее со
храненная функция по-прежнему будет возвращать квадрат аргумента:
при каждом обращении к фабричной функции, как в данном примере, произведенные ею функции сохраняют свой
собственный блок данных с информацией о состоянии. В нашем случае благодаря тому, что каждая из функций получает свой собственный блок данных с информацией о состоянии, функция, которая присваивается имени g, запо минает число 3 в переменной N функции maker, а функция f – число 2.

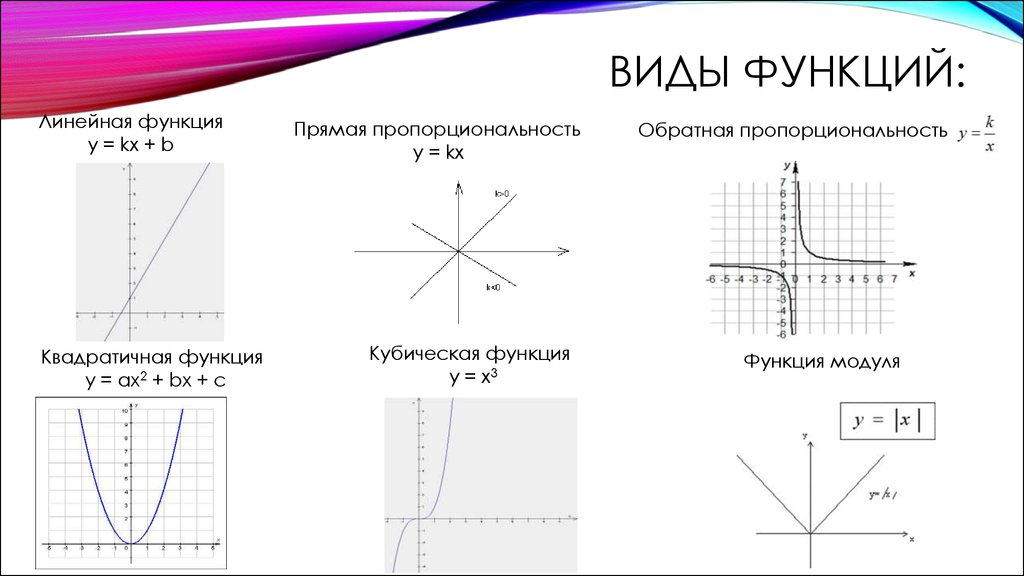








Где используется?
- lambda
- декораторы
Лучше для хранения информации подходят классы или глобальные переменные.
Свойства rest/spread
Одно из наиболее интересных свойств добавленных в ES2015 был оператор spread. Этот оператор делает операции копирования и объединения массивов намного легче. Вместо вызова методов или , можно просто использовать оператор
const arr1 = ; // make a copy of arr1 const copy = ; console.log(copy); // → const arr2 = ; // merge arr2 with arr1 const merge = ; console.log(merge); // →
Оператор spread так же удобен в ситуациях массив должен быть передан в качестве отдельного аргумента в функцию. Для примера:
const arr = // equivalent to // console.log(Math.max(10, 20, 30)); console.log(Math.max(...arr)); // → 30
ES2018 дополнительно расширяет этот синтаксис, добавляя свойства spread к литеральным объектам. С помощью свойств spread вы можете скопировать собственные перечисляемые свойства объекта в новый объект. Рассмотрим следующий пример:
const obj1 = {
a: 10,
b: 20
};
const obj2 = {
...obj1,
c: 30
};
console.log(obj2); // → {a: 10, b: 20, c: 30}
В коде, оператор был использован для получения свойств объекта и назначению их объекту . До появления ES2018, подобная конструкция вызвала бы ошибку. Если будут определены несколько свойств с одинаковыми именами то останутся только те которые были последними:
const obj1 = {
a: 10,
b: 20
};
const obj2 = {
...obj1,
a: 30
};
console.log(obj2); // → {a: 30, b: 20}
Свойство spread так же предоставляет новый путь объединения двух и более объектов, вместо использования метода :
const obj1 = {a: 10};
const obj2 = {b: 20};
const obj3 = {c: 30};
// ES2018
console.log({...obj1, ...obj2, ...obj3}); // → {a: 10, b: 20, c: 30}
// ES2015
console.log(Object.assign({}, obj1, obj2, obj3)); // → {a: 10, b: 20, c: 30}
Однако обратите внимание, что оператор spread не всегда дает тот же результат что и. Рассмотрим следующий код:
Object.defineProperty(Object.prototype, 'a', {
set(value) {
console.log('set called!');
}
});
const obj = {a: 10};
console.log({...obj});
// → {a: 10}
console.log(Object.assign({}, obj));
// → set called!
// → {}
В этом коде, метод вызывает унаследованое свойство сеттера. И наоборот, оператор spread игнорирует свойство сеттера.
В следующем примере, свойство не будет скопировано потому что его атрибут установлен в :
const car = {
color: 'blue'
};
Object.defineProperty(car, 'type', {
value: 'coupe',
enumerable: false
});
console.log({...car}); // → {color: "blue"}
Унаследованные свойство так же игнорируются даже если они перечисляемые:
const car = {
color: 'blue'
};
const car2 = Object.create(car, {
type: {
value: 'coupe',
enumerable: true,
}
});
console.log(car2.color); // → blue
console.log(car2.hasOwnProperty('color')); // → false
console.log(car2.type); // → coupe
console.log(car2.hasOwnProperty('type')); // → true
console.log({...car2}); // → {type: "coupe"}
В этом коде, наследует совойство от . Так как оператор spread копирует только собственные свойство объекта, не копируется.
Так же имейте в виду что оператор spread может сделать только поверхностную копию объекта. Если свойство содержит объект, будет скопирована только ссылка на объект:
const obj = {x: {y: 10}};
const copy1 = {...obj};
const copy2 = {...obj};
console.log(copy1.x === copy2.x); // → true
Свойство в ссылается на тоже самый объект в памяти что и в , поэтому оператор сравнения возвращает .
Еще одна полезная функция, добавленная в ES2015, — это rest параметры, которые позволяют использовать … для представления значений как массив. Например:
const arr = ; const = arr; console.log(x); // → 10 console.log(rest); // →
Здесь, первый элемент в назначен переменной , а оставшиеся элементы назначены переменной . Этот паттерн, называемый деструктуризацией массива, стал настолько популярным, что технический комитет Ecma решил привнести аналогичную функциональность в объекты:
const obj = {
a: 10,
b: 20,
c: 30
};
const {a, ...rest} = obj;
console.log(a); // → 10
console.log(rest); // → {b: 20, c: 30}
Этот код использует свойство rest для копирования оставшиеся перечисляемых свойств в новый объект
Обратите внимание что rest свойства всегда должны быть в конце объекта, иначе будет ошибка:
const obj = {
a: 10,
b: 20,
c: 30
};
const {...rest, a} = obj; // → SyntaxError: Rest element must be last element
Также имейте в виду, что использование нескольких rest в объекте вызывает ошибку, если они не являются вложенными:
const obj = {
a: 10,
b: {
x: 20,
y: 30,
z: 40
}
};
const {b: {x, ...rest1}, ...rest2} = obj; // no error
const {...rest, ...rest2} = obj; // → SyntaxError: Rest element must be last element
Поддержка свойств Rest/Spread
| Chrome | Firefox | Safari | Edge |
|---|---|---|---|
| 60 | 55 | 11.1 | No |
| Chrome Android | Firefox Android | iOS Safari | Edge Mobile | Samsung Internet | Android Webview |
|---|---|---|---|---|---|
| 60 | 55 | 11.3 | No | 8.2 | 60 |
Node.js:
- 8.0.0 (требует флаг )
- 8.3.0 (полная поддержка)
Хранение данных
Пример демонстрирует получение данных отображения. Нужны для показа статичной информации. Давайте посмотрим, как они хранятся и используются в приложении.
В примере выше экспортировали инстанс класса-стора. Создавали его рядом с объявлением. Однако, вынесем создание инстанса в контекст компонента, который его использует. Глобальные состояния заменяются контекстом. Степень зацепления между ui и сервисами уменьшается. Используемые сущности удалятся с анмаунтом компонента.
Теперь можно использовать сущности. Их получили через геттер стора.
Что делать, если нужно создать новый фильм? Тогда данные, которые отправляем на бэкенд, должны быть реактивными на фронтенде. Но также должны храниться отдельно от данных ввода. Нам нужна «обертка», которая хранит состояние, обновляет его, позволяет считывать и гарантирует типизацию. Для ее создания используем observable класс библиотеки mobx. Создадим класс Model, от которого будем наследовать «обертки».
Обновление данных из формы создания происходит в подклассе Model. В конструктор по умолчанию передается объект с пустыми значениями. Это происходит, чтобы создавать готовую модель.
Теперь добавим метод в сервис детального фильма. Он будет отправлять запрос на создание фильма. Обновление данных формы будет реализовываться через использование model.
Далее можно использовать model и метод сервиса в ui. Model — часть ui-адаптера. Она хранит и обновляет данные. Потом отправит в метод сервиса.
Если же нужно обновить, например, оценку фильма, можно создать еще один метод сервиса. Он отправит запрос на бэкенд и получит обновленные данные. Далее создаст новую сущность фильма и перезапишет state.
Теперь используем метод сервиса в ui через контекст.
В этом примере данные фильма хранятся в контексте компонента страницы. Но они могут понадобиться всему приложению. Что тогда делать? Есть выход.
Например, данные текущего пользователя хранятся в контексте компонента App, то есть в контексте всего приложения. Можно получить единственный вид с бэкенда, который должен сохраняться между обновлениями страницы.
Есть два пути — в Cookies или в LocalStorage. Куки хранят не более 4096 байт информации. Обычно там находятся данные, нужные серверу, например, токены авторизации.
Если имеем дело с данными, которые нужны только клиентской части приложения, то складываем их в LocalStorage. Например, о выбранной теме приложения или языке.
Проектирование структуры состояния¶
В Redux все состояние приложения хранится в виде единственного объекта. Подумать о его структуре перед написанием кода — довольно неплохая идея. Каково минимальное представление состояния Вашего приложения в виде объекта?








Для нашего todo-приложения, мы хотим хранить две разные сущности:
- Состояние фильтра видимости;
- Актуальный список todo-задач.
Часто вы будете понимать, что вам нужно хранить некоторые данные, а также некоторые состояния пользовательского интерфейса в дереве состояний. Это нормально, только старайтесь такие данные не смешивать с данными, которые описывают состояние UI.
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Заметка об отношениях
В более сложном приложении вы, скорее всего, будете иметь разные сущности, которые будут ссылаться друг на друга. Мы советуем поддерживать состояние (state) в настолько упорядоченном виде, насколько это возможно. Старайтесь не допускать никакой вложенности. Держите каждую сущность в объекте, который хранится с ID в качестве ключа. Используйте этот ID в качестве ссылки из других сущностей или списков. Думайте о состоянии приложения (app state), как о базе данных. Этот подход детально описан в документации к normalizr. Например, в реальном приложении хранение хеша todo-сущностей и массива их ID в состоянии (state) было бы лучшей идеей, но мы оставим пример простым.
Разрешение имен: правило LEGB
Для инструкции def:
- Поиск имен ведется самое большее в четырех областях видимости: локальной, затем в объемлющей функции (если таковая имеется), затем в глобальной и, наконец, во встроенной.
- По умолчанию операция присваивания создает локальные имена.
- Объявления global и nonlocal отображают имена на область видимости вмещающего модуля и функции соответственно.
Правило LEGB:
-
Когда внутри функции выполняется обращение к неизвестному имени, интерпретатор пытается отыскать его в четырех областях видимости – в локальной (local, L), затем в локальной области любой объемлющей инструк-
ции def (enclosing, E) или в выражении lambda, затем в глобальной (global, G) и, наконец, во встроенной (built-in, B).- Поиск завершается, как только будет найдено первое подходящее имя.
- Если требуемое имя не будет найдено, интерпретатор выведет сообщение об ошибке.
-
Когда внутри функции выполняется операция присваивания (а не обращение к имени внутри выражения), интерпретатор всегда создает или изменяет имя в локальной области видимости, если в этой функции оно не было
объявлено глобальным или нелокальным. - Когда выполняется присваивание имени за пределами функции (то есть на уровне модуля или в интерактивной оболочке), локальная область видимости совпадает с глобальной – с пространством имен модуля.

Это правила поиска имен переменных. Для атрибутов объектов применяются другие правила (см. Наследование).
- Глобальные имена: X, func (так как объявлены на верхнем уровне модуля)
- Локальные имена: Y (аргументы передаются через присвоение), Z (создается через =)
Методы .status() и .append()
Метод .send() объекта res пересылает клиентской стороне любые данные, переданные в качестве аргумента. Метод может принимать в качестве аргумента строку, массив и объект.
Откройте файл index.js и реализуйте запрос GET с маршрутом ‘/home’:
app.get('/home', (req, res) => {
res.send('Hello World!'))
});
Обратите внимание, GET-запрос принимает callback аргумент с req и res в качестве аргументов. Вы можете использовать объект res в GET-запросе, чтобы отправить клиенту строку «Hello World!». Метод .send() также изначально определяет собственные встроенные заголовки в зависимости от Content-Type и Content-Length данных
Метод .send() также изначально определяет собственные встроенные заголовки в зависимости от Content-Type и Content-Length данных.
Объект res может определять HTTP-коды состояния. Это делается с помощью метода .status(). В файле index.js интегрируйте метод .status() в объект res и передайте код состояния в качестве аргумента:
res.status(404).send('Not Found');
Метод .status() объекта res установит код состояния 404. Чтобы отправить код состояния на клиентскую сторону, вы можете использовать цепочку методов с помощью .send(). Код состояния 404 сообщает клиентской стороне, что запрошенные данные не найдены.
Метод .sendStatus() – это сокращенный синтаксис, который обеспечивает функциональность методов .status() и .send():
res.sendStatus(404);
Здесь метод .sendStatus() устанавливает код состояния 404 и отправляет его клиентской стороне – все это за один вызов.
Коды состояния HTTP обобщают ответ вашего сервера Express. Браузеры используют эти коды, чтобы сообщить клиентской стороне, существуют ли указанные данные и не возникает ли внутренних ошибок сервера.
Чтобы определить заголовок в ответе сервера, примените метод .append(). В вашем файле index.js при вызове .append() передайте заголовок в качестве первого аргумента и значение в качестве второго:
res.append('Content-Type', 'application/javascript; charset=utf-8');
res.append('Connection', 'keep-alive')
res.append('Set-Cookie', 'divehours=fornightly')
res.append('Content-Length', '5089990');
В рамках одной строки кода метод .append() принимает стандартные и нестандартные заголовки в ответе вашего сервера.
Преимущества и недостатки рекурсивных и итеративных подходов
В мире программирования и информатики существует два основных подхода к решению задач — рекурсивный и итеративный. Оба этих подхода имеют свои преимущества и недостатки, и могут применяться для решения различных типов задач.
Рекурсивный подход — это метод решения задачи, при котором функция вызывает саму себя внутри своего тела. Этот подход основывается на принципе разделения сложной задачи на более простые подзадачи. Рекурсивное решение требует меньше кода и может быть более компактным и понятным в реализации, особенно когда задача имеет рекурсивную структуру. Он также может обладать лучшей читабельностью и логичностью программного кода.
Однако рекурсивный подход может иметь некоторые недостатки. Во-первых, он может быть менее эффективным по времени выполнения и требовать больше ресурсов, так как каждый новый вызов функции создает дополнительные затраты на память и время. Во-вторых, рекурсия может привести к возникновению «бесконечной рекурсии» — ситуации, когда функция вызывает саму себя бесконечное количество раз, что приводит к переполнению стека вызовов программы и ее аварийному завершению.
Итеративный подход — это метод решения задачи, основанный на использовании циклов и итераций. В отличие от рекурсивного подхода, итеративный подход выполняет повторяющиеся действия в цикле до достижения желаемого результата. Этот подход обычно более эффективен по времени выполнения и требует меньших ресурсов, так как не создает новых вызовов и не вызывает переполнение стека. Он также более предсказуем и позволяет лучшую контролируемость в решении задачи.
Тем не менее, итеративный подход может быть более сложным в реализации и содержать больше кода, особенно в случае сложных задач с большим количеством повторений. Он также может быть менее интуитивным и менее гибким в сравнении с рекурсивным подходом, особенно если задача имеет рекурсивную структуру.
В итоге, выбор между рекурсивным и итеративным подходом зависит от конкретных особенностей задачи, требований по эффективности и понятности кода. Следует выбрать подход, который наилучшим образом соответствует поставленной задаче и помогает достичь требуемого результата.
Архитектура REST
Чтобы понять, как работает REST API, нужно подробнее рассмотреть, что представляет собой стиль архитектуры программного обеспечения REST.
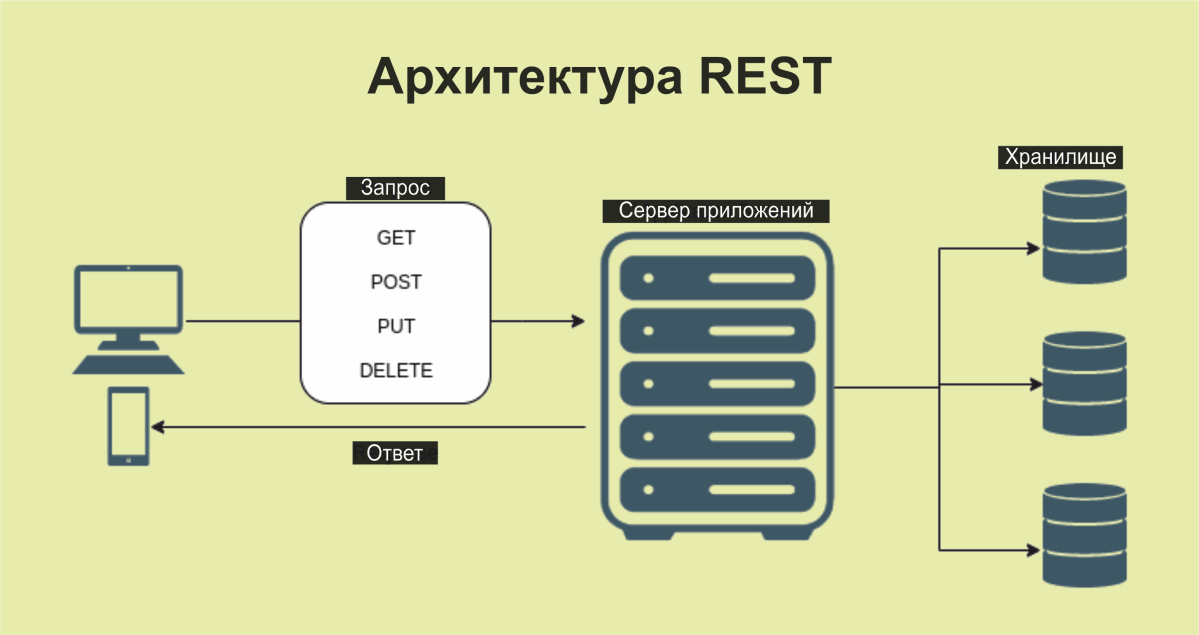
REST API используются для доступа к данными и их обработки с помощью стандартного набора операций без сохранения состояния. Эти операции являются неотъемлемой частью протокола HTTP. Они представляют собой основные функции создания («create»), чтения («read»), модификации («update») и удаления («delete») и обозначаются акронимом CRUD.
Операциям REST API соответствуют, хотя и не полностью идентичны, следующие методы HTTP:
- POST (создание ресурса или предоставление данных в целом).
- GET (получение индекса ресурсов или отдельного ресурса).
- PUT (создание и замена ресурса).
- PATCH (обновление/изменение ресурса).
- DELETE (удаление ресурса).
С помощью этих HTTP-методов и имени ресурса в качестве адреса, мы можем построить REST API, создав конечную точку для каждой операции. В результате мы получим стабильную и легко понятную основу, которая позволит быстро дорабатывать код и осуществлять его дальнейшее сопровождение.
Та же основа будет применяться для интеграции сторонних функций, о которых было сказано чуть выше. Большинство из них тоже использует REST API, что ускоряет такую интеграцию.
Функция внутри другой функции

Внутри функции️ можно размещать другие функции️. Например функция️ вернет цифру , значение которой выведем через вызов функции️ .




Интерактивный редактор
function learnJavaScript() {
function showNumberFive() {
return 5
}
return showNumberFive()
}
functionlearnJavaScript(){
functionshowNumberFive(){
return5
}
returnshowNumberFive()
}
Результат
Давайте рассмотрим всё это шаг за шагом:
- Ключевое слово указывает интерпретатору на то, что следующий далее код является пользовательским, то есть созданной Вами, а не встроенной функцией.
- Написанное верблюжьимРегистром является пользовательским названием этой функции. Для интерпретатора в общем‑то нет разницы, как именно называется эта функция, но лучше давать функциям названия, из которых чётко следует, что именно они делают.
- скобки обязательный элемент любой функции. Порой в скобки заключается одна, две и более переменных , в нашем случае в скобках нет ничего.
- В фигурные скобки должно быть заключено само тело функции — суть алгоритма программы.
- Само тело функции принято выделять отступами справа (при помощи клавиши TAB). Это не обязательно для выполнения программы, но обязательно для коллективной работы, поскольку значительно облегчает читабельность кода.
- Ключевое слово означает, что всякий раз когда мы вызываем эту функцию, значение будет передано, то есть «возвращено», интерпретатору, поэтому оно называется «возвращаемое значение функции».
Синхронные и Асинхронные Обратные вызовы
Выполняется ли обратный вызов синхронно или асинхронно, зависит от функции, которая его вызывает. Давайте рассмотрим пару примеров.
Синхронные функции обратного вызова
Когда код является синхронным, он выполняется сверху вниз, строка за строкой. Операции выполняются одна за другой, при этом каждая операция ожидает завершения предыдущей. Мы уже видели пример выше синхронного обратного вызова в функции .
Чтобы ещё больше проиллюстрировать это, вот демонстрация, в которой используется как , так и для вычисления максимального чиста в списке чисел, разделённых запятыми:
Основное действие происходит здесь:
Двигаясь сверху вниз, делаем следующее:
- Получаем пользовательский ввод.
- Удаляем все пробелы.
- С помощью создаём массив строк используя в качестве разделителя.
- Используя преобразуем каждый элемент массива в число.
- Используем для перебора массива и поиска наибольшего числа.
Почему бы вам не поиграть с кодом на CodePen? Попробуйте изменить обратный вызов для получения другого результата (например, для поиска наименьшего числа или всех нечётных числе и т.д.).
Асинхронные функции обратного вызова
В отличие от синхронного кода, асинхронный код JavaScript не будет выполняться сверху вниз, строка за строкой. Вместо этого асинхронная операция зарегистрирует функцию обратного вызова, которая будет выполнена после её завершения. Это означает, что интерпретатору JavaScript не нужно завершения асинхронной операции, а вместо этого он может выполнять другие задачи во время её выполнения.
Одним из основных примеров асинхронного кода является получение данных из удалённого API. Давайте посмотрим на пример и разберём как он использует обратные вызовы.
Основное действие происходит здесь:
Код в приведённом выше примере использует для отправки запроса списка фиктивных пользователей в фэйковом JSON API. Как только сервер возвращает ответ, мы запускаем нашу первую функцию обратного вызова, которая пытается преобразовать этот ответ в JSON. После этого запускается вторая функция обратного вызова, создающая список имён пользователей и добавляющая их в список
Обратите внимание, что внутри второго обратного вызова мы используем ещё два вложенных обратных вызова для выполнения работы по извлечению имён и созданию элементов списка
Ещё раз, я бы посоветовал вам поиграть с кодом. Если ознакомитесь с документацией по API, вы найдёте множество других ресурсов, которые вы можете получить и использовать.
Итоги
Как мы видим, REST API не случайно стал таким популярным. Повторим основные его отличия:
- REST — это архитектурный стиль API. Он не ограничивается никакими протоколами и не имеет собственных методов. Но обычно в RESTful-сервисах используют стандарт HTTP, а файлы передают в формате JSON или XML.
- Есть шесть принципов, на которых строится REST: клиент-серверная модель, отсутствие состояния, кэширование, единообразие интерфейса, многоуровневая система, код по требованию. Последний из них необязателен.
- REST-подход к архитектуре позволяет сделать сервисы отказоустойчивыми, гибкими и производительными, а при их масштабировании и внесении изменений не возникает больших сложностей.
Вывод
Мы изучили пример организации работы с данными во фронтенд приложении. Из него можно выделить несколько общих советов. Они помогут при разработке:
Сервис взаимодействия фронтенда с бэкендом должен формировать функции запросов. В них передается конфиг. После чего для отправки запроса нужно всего лишь передать функциям динамические данные при их вызове.
Реализовывайте миддлвары запросов. Позволяют расширить возможности взаимодействия с сервером. Это происходит без модификации api-класса или возвращаемых им функций;
Разделяйте структуры данных. Используются во фронт-приложении и приходят с бэкенда. Даже простое разделение интерфейсов объектов бизнес-логики и DTO может спасти от проблем;
Тайпскрипт не способен типизировать даннные в рантайме
Для этого используйте тайпгарды или готовые библиотеки;
Приложение важно разделять на слои — инфраструктурный, сервисный и доменный. Инфраструктурный соединяет приложение с бэкендом и ui. Доменный хранит бизнес-данные и реализует бизнес-логику
Сервисный предоставляет точку связи между ними;
Нужные компонентам данные стоит хранить в их контексте;
Данные, которые должны сохраняться между обновлениями страницы, храните в Cookies или LocalStorage.
Реализовывать эти советы возможно и с помощью других решений. Например, структуру приложения можно задать через паттерн Model-Constructor-Serialazier или через методологию Feature-Sliced Design. А для декодирования json реально использовать runtypes или кастомные тайпгарды. Но реализация советов, которые предлагаем мы, решит следующие проблемы:
- Позволит упростить и ускорить добавление новых запросов на бэкенд;
- Предоставит возможность быстро расширять функционал работы с запросами;
- Упростит обработку ошибок;
- Ускорит время актуализации фронтенда под изменения бэкенда.
- Увеличит устойчивость фронтенда к изменениям бэкенда;
- Отвяжет этапы обработки данных друг от друга — api-запросы, бизнес-логику и отображение. Это позволит проще и быстрее вносить изменения в процесс работы на любом из этапов;
- Уменьшит вероятность багов, связанных с хранением данных.