
Структуры (struct)
В отличие от массива, все элементы которого однотипны, структура может содержать элементы разных типов. В языке C++ структура является видом класса и обладает всеми его свойствами, но во многих случаях достаточно использовать структуры так, как они определены в языке С:
struct {
тип_1 элемент_1:
тип_2 элемент_2;
тип_n элемент_n;
} ;
Элементы структуры называются полями структуры и могут иметь любой тип, кроме типа этой же структуры, но могут быть указателями на него. Если отсутствует имя типа, должен быть указан список описателей переменных, указателей или массивов. В этом случае описание структуры служит определением элементов этого списка:
// Определение массива структур и указателя на структуру:
struct {
char f1o;
int date, code;
double salary;
}staff, *ps;
Если список отсутствует, описание структуры определяет новый тип, имя которого можно использовать в дальнейшем наряду со стандартными типами, например:
struct Worker{ // описание нового типа Worker
char f1o;
int date, code;
double salary;
}; // описание заканчивается точкой с запятой
// определение массива типа Worker и указателя на тип Worker:
Worker staff, *ps;
Имя структуры можно использовать сразу после его объявления (определение можно дать позднее) в тех случаях, когда компилятору не требуется знать размер структуры, например:
struct List;. // объявление структуры List
struct Link{
List *p; // указатель на структуру List
Link *prev, *succ; // указатели на структуру Link
};
struct List { / * определение структуры List * / };
Это позволяет создавать связные списки структур.
Для инициализации структуры значения ее элементов перечисляют в фигурных скобках в порядке их описания:
struct{
char fio;
int date, code;
double salary;
}worker = {«Страусенке». 31. 215. 3400.55};
При инициализации массивов структур следует заключать в фигурные скобки каждый элемент массива (учитывая, что многомерный массив — это массив массивов):
struct complex{
float real, im;
} compl = {
{{1. 1}. {1. 1}. {1. 1}}. // строка 1. TO есть массив compl
{{2. 2}. {2. 2}. {2. 2}} // строка 2. то есть массив compl
};
Для переменных одного и того же структурного типа определена операция присваивания, при этом происходит поэлементное копирование. Структуру можно передавать в функцию и возвращать в качестве значения функции. Другие операции со структурами могут быть определены пользователем. Размер структуры не обязательно равен сумме размеров ее
элементов, поскольку они могут быть выровнены по границам слова.
Доступ к полям структуры выполняется с помощью операций выбора . (точка) при обращении к полю через имя структуры и -> при обращении через указатель, например:
Worker worker, staff, *ps;
worker.fio = «Страусенке»;
staff.code = 215;
ps->salary = 0.12;
Если элементом структуры является другая структура, то доступ к ее элементам выполняется через две операции выбора:
struct А {int а; double х;};
struct В {А а; double х;} х;
х.а.а = 1;
х.х = 0.1;
Как видно из примера, поля разных структур могут иметь одинаковые имена, поскольку у них разная область видимости. Более того, можно объявлять в одной области видимости структуру и другой объект (например, переменную или массив) с одинаковыми именами, если при определении структурной переменной использовать слово struct, но не советую это делать — запутать компилятор труднее, чем себя.
Битовые поля
Битовые поля — это особый вид полей структуры. Они используются для плотной упаковки данных, например, флажков типа «да/нет». Минимальная адресуемая ячейка памяти — 1 байт, а для хранения флажка достаточно одного бита. При описании битового поля после имени через двоеточие указывается длина поля в битах (целая положительная константа):
struct Options{
bool centerX:1;
bool centerY:1;
unsigned int shadow:2;
unsigned int palette:4;
};
Битовые поля могут быть любого целого типа. Имя поля может отсутствовать, такие поля служат для выравнивания на аппаратную границу. Доступ к полю осуществляется обычным способом — по имени. Адрес поля получить нельзя, однако в остальном битовые поля можно использовать точно так же, как обычные поля структуры. Следует учитывать, что операции с отдельными битами реализуются гораздо менее эффективно, чем с байтами и словами, так как компилятор должен генерировать специальные коды, и экономия памяти под переменные оборачивается увеличением объема кода программы. Размещение битовых полей в памяти зависит от компилятора и аппаратуры.
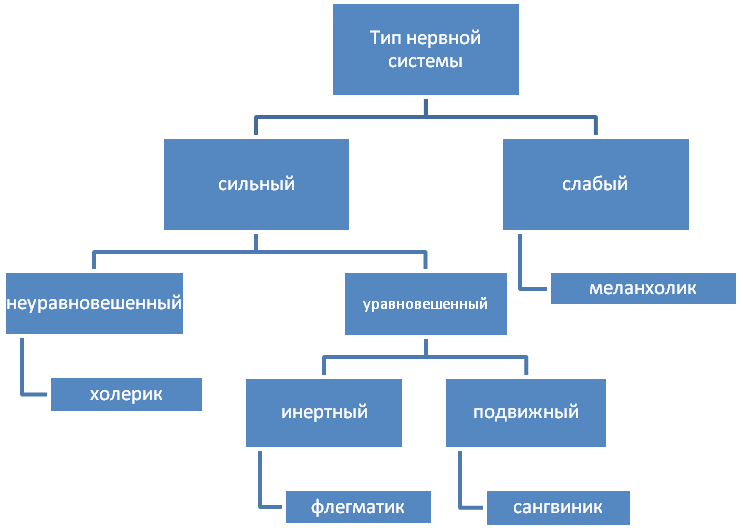
Основные принципы типирования людей
Типирование – это способ классификации людей по определенным признакам с целью выделения их особенностей и выработки индивидуальной стратегии взаимодействия. Основные принципы этого подхода включают в себя следующие факторы:
- Индивидуальность. Каждый человек уникален и имеет свои особенности, которые необходимо учитывать при типировании.
- Объективность. Типирование должно основываться на объективных данных, таких как личностные тесты и анализ поведения человека в различных ситуациях.
- Комплексность. Человек должен типироваться как единое целое, учитывая все аспекты его личности, включая профессиональные и личные характеристики.
- Динамичность. Личность человека может изменяться со временем под влиянием различных факторов, и типирование должно учитывать эти изменения.
Основой типирования является использование психологических тестов для определения личностных характеристик, таких как темперамент, интровертированность или экстравертированность, стрессоустойчивость и др. Для более точной и полной классификации также могут применяться методы анализа жизненного опыта, мотиваций и профессиональных навыков.
Типирование может применяться в различных областях, включая образование, психологию, маркетинг и управление персоналом. Основная цель этого подхода – улучшение взаимодействия между людьми и повышение эффективности в работе и общении.
Примеры типирования
Некоторые примеры применения типирования:
- В школах и вузах для определения ученических личностных характеристик и разработки индивидуальных учебных стратегий.
- В бизнесе для подбора персонала, оценки кандидатов и разработки индивидуальных мотивационных программ для сотрудников.
- В спорте для определения возможностей и потенциала спортсменов при подборе состава команды и разработке индивидуальных тренировочных программ.
Примечания[править | править код]
- , p. 1.
- , p. 1.
- ↑ , с. 208.
- ↑ Andrew Cooke. Introduction To Computer Languages. Дата обращения: 13 июля 2012.
- .
- Existential types on HaskellWiki. Дата обращения: 15 июля 2014. Архивировано 20 июля 2014 года.
- . Дата обращения: 15 июля 2014. Архивировано 21 апреля 2016 года.
- Standard ECMA-334 Архивная копия от 31 октября 2010 на Wayback Machine, 8.2.4 Type system unification.
- .
- Amanda Laucher, Paul Snively. Types vs Tests (англ.). InfoQ. Дата обращения: 26 февраля 2014. Архивировано 2 марта 2014 года.
- Adobe and Mozilla Foundation to Open Source Flash Player Scripting Engine. Дата обращения: 26 февраля 2014. Архивировано 21 октября 2010 года.
- Psyco, a Python specializing compiler. Дата обращения: 26 февраля 2014. Архивировано 29 ноября 2019 года.
Основные методы и технологии
1. Тестирование личности. Этот метод основывается на использовании специальных тестов, которые позволяют определить тип личности человека. Например, такие тесты могут измерить уровень тревожности, склонность к агрессии, уверенность в себе и другие характеристики.
2. Анализ физических параметров. Этот метод основывается на анализе физических параметров человека, таких как размеры тела, форма черепа, структура глаз и т. д. Например, с помощью этого метода можно определить тип внешности человека и его склонность к определенным характеристикам.
3. Социальный анализ. Этот метод основывается на анализе социальной ситуации, в которой живет человек, его общения, интересов и т. д. Например, с помощью этого метода можно определить, к какой социальной группе принадлежит человек, какие ценности он разделяет и т. д.
4. Анализ личных предпочтений. Этот метод основывается на анализе личных предпочтений и интересов человека. Например, можно изучить, какие виды деятельности или развлечений предпочитает человек, какие книги читает, какие фильмы смотрит и т. д.
5. Методика множественного интеллекта. Этот метод основывается на идее, что у человека есть несколько видов интеллекта, которые вместе определяют его способности и склонности. Например, с помощью этого метода можно оценить уровень интеллектуальных способностей человека в разных областях, таких как математика, лингвистика, музыка и т. д.
- Все эти методы и технологии могут использоваться для типирования людей. Однако, каждый из них имеет свои преимущества и недостатки, и никакой метод не является идеальным.
- Поэтому, для получения наиболее точных результатов, часто используется комбинирование разных методов и технологий.
Зачем делают прототипы
Главная цель прототипирования — сэкономить деньги и время. С первого раза сложно создать идеальный продукт, который понравится заказчику, а главное — будет удобен для пользователей.
Ценность прототипов в том, что они помогают верхнеуровнево взглянуть на продукт, его структуру и идею, а также быстро и схематично показать концепт. Если собранный в прототипе продукт выглядит юзабельным без итогового дизайна, анимации и маркетинговых фич — он жизнеспособный.
Проверять, так ли это, лучше всего с помощью кликабельных прототипов, которые достаточно быстро можно собрать с помощью Figma. Как их делать, можно посмотреть в уроке от Алексея Бычкова.



Дизайн-директор Mailfit
Прототип позволяет протестировать выбранный вариант решения без больших вложений, при необходимости внести правки и только потом приступать к разработке дизайна и программированию.
Прототипирование решает несколько важных задач:
- Поиск лучших идей. Прототип делается быстро, поэтому можно сразу подготовить несколько вариантов для тестирования гипотез, чтобы потом выбрать наиболее удачный. Это особенно актуально для стартапов.
- Выявление ошибок. На этапе создания макета можно отследить ключевые недочёты будущего сайта или приложения. На их исправление вы затратите меньше времени, денег и усилий, чем если бы пришлось вносить корректировки в конечный продукт.
- Оценка юзабилити. Разработка прототипов и тестирование на них пользовательских сценариев — отличная возможность как можно раньше проверить, насколько решение удобно для пользователей.
Прототипы помогают последовательно вносить правки в проект и согласовывать каждый этап с заказчиком. Источник
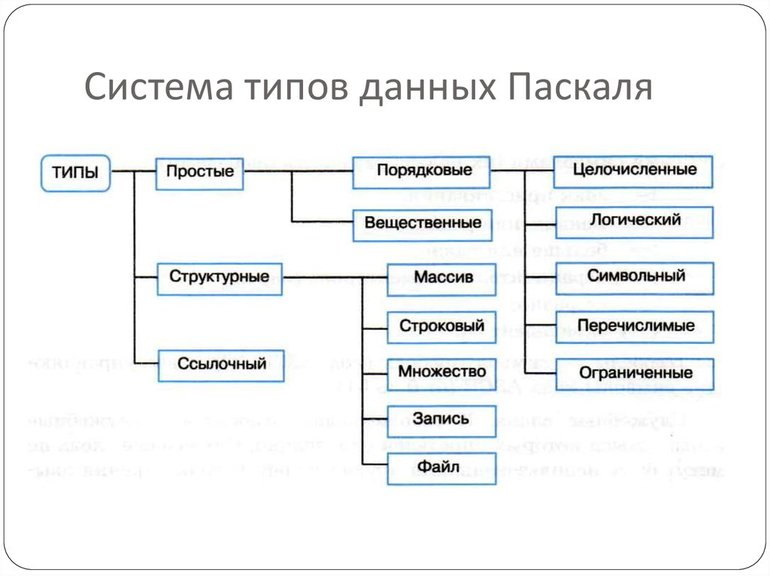
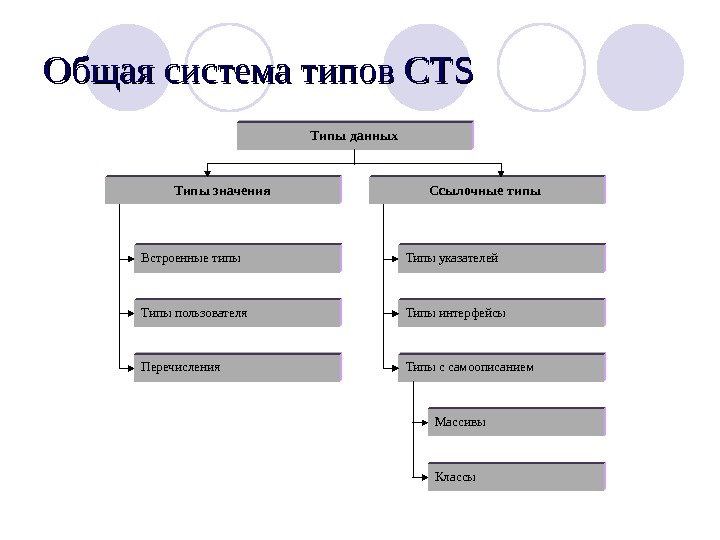
Примитивные типы данных
Примитивные типы данных — это базовые типы данных языка программирования. Их ключевая особенность в том, что данные в них, в отличие от ссылочных типов, располагаются непосредственно на участке памяти компьютера в котором находится переменная. Перечислим и опишем основные примитивные типы данных в программировании.
- Логический тип данных или булевый. Переменные данного вида могу принимать лишь два значения: истина (true, либо 1) или ложь (false, либо 0). В различных языках программирования булевы переменные объявляются с помощью ключевого слова bool либо boolean. Логический тип данных имеет широчайшее применение (как собственно и другие типы). Например, он фигурирует в условных операторах ветвления (if) и операторах цикла (for, while, do-while).
-
Целочисленный тип данных. Обычно объявляется ключевым словом int или integer. Переменные данного типа могут принимать только целочисленные значения. Часто тип int занимает четыре байта (232 = 4294967296), следовательно переменные могут принимать значения от — 2 147 483 648 и до 2 147 483 647 в случае, когда целый тип учитывает знак числа. Если использовать беззнаковый целый тип данных (unsigned int), то его диапазон значений от 0 до 4294967295. В языке программирования Java целый тип всегда 4 байта. В языках Си и C# предполагаемый размер также 4 байта, но на деле — всё зависит от конкретной реализации языка на программной платформе.
Данный тезис относится не только к типу int. Размер каждого примитивного типа данных в любой реализации языка Java всегда строго определен и одинаков. В C-подобных языках это не так. - Целочисленный тип byte. Исходя из названия типа, он занимает в памяти один байт, то есть восемь бит. 28 = 256 — такое количество значений он может в себя вместить. Если говорить конкретно, то в случае, если тип byte со знаком, то диапазон от -128 до 127 (не забываем, что есть еще число ноль); когда byte беззнаковый, то от 0 до 255.
- Короткий целый тип short. В памяти для него выделено 2 байта = 16 бит (216 = 65536). Диапазон принимаемых значений типом short со знаком — это .
- Длинный целый тип long. Длинный целый тип занимает в памяти 8 байт, то есть 64 бита. 264 = 1,8446744 × 1019. Диапазон допустимых значений очень велик: в случае знакового типа, это . Кроме того, модификатор long можно использовать в сочетании с другими типами (long пишется перед названием типа, например: long double), расширяя, тем самым, диапазон допустимых значений типа согласно спецификации конкретного языка программирования.
- Число с плавающей запятой. Этот тип обозначается ключевым словом float, также же этот тип называют вещественным типом одинарной точности. float — это ни что иное, как десятичная дробь (привычная нам на письме), но в памяти компьютера она представляется в виде экспоненциальной записи: состоит из мантиссы и показателя степени. Например: 0,0506 = 506,0 ⋅ 10-4, где 506 — мантисса, а -4 — показатель степени десяти. Размер типа данных float в спецификации языка Си четко не определен.
- Число с плавающей запятой двойной точности — это тип double. Данный тип схож с типом float, единственное их различие — это размер в памяти и, соответственно, диапазон принимаемых значений. Естественно тип double больше; но всё зависит от реализации языка, говоря строго: тип double по крайней мере должен быть не меньше, чем float.
- Символьный тип данных занимает в памяти один байт — если используется кодировка ASCII и два байта — если установлена кодировка Unicode. Данный тип по сути является целым числом. Цифра, хранящаяся в переменной символьного типа — это номер символа в таблице кодировки. Обычно объявляется с помощью ключевого слова char. Нужно четко представлять себе, что char — это число, и работать с ним, как с числом, в некоторых случаях очень удобно и эффективно.

Ключевая особенность примитивных типов данных в том, что они передаются по значению. Это значит, что при передачи переменной в качестве аргумента функции (или методу) она копируется туда. Следовательно манипуляции, производимые с переменной в вызванной функции, никак не повлияют на значение переменной в вызывающей функции.
Примечание: модификатор unsigned (то есть беззнаковый) применим к любому целочисленному типу (в том числе и к символьному), а long (длинный) применим практически к любому типу, за исключением логического.
Массив как производный тип данных
Номер элемента в последовательности называется индексом.
В языке Си количество элементов в массиве должно быть определено во время трансляции (задано константой) и
не может быть изменено в процессе выполнения программы.
Элементы массива размещаются в памяти последовательно и нумеруются от до n-1, где n — их количество в массиве. Пример определения массива :
C
Важная особенность массивов в Си: во время работы программы контроль за нахождением индексов в пределах размерности массива не производится. В случае выхода за пределы массива будут использованы значения переменных в соседних областях памяти и результат работы программы будет непредсказуем.
Динамическая типизация на примере Ruby
Впоследствии, в противовес статической типизации была разработана модель динамически типированных языков. При таком подходе, переменная не имеет заранее определенного типа, а принимает тип при инициализации и при присвоении ей некоторого значения. Таким образом, в различных участках программы одна и та же переменная может принимать значения разных типов.
На первый взгляд это может показать странным, особенно с точки зрения программиста, привыкшего к статически типированным языкам (таким как С++ или Паскаль). На самом деле здесь нет ничего страшного или нелогичного. Все мы в своей жизни, сами того не подозревая, оперируем понятиями динамических переменных. Один и тот же объект в разных ситуациях мы можем воспринимать с разных точек зрения. Задавая вопрос «как пройти в библиотеку», мы можем получить как конкретный ответ «в 3 часа ночи?! идиот!» так и целый набор: «на автобусе номер 23, на такси или пешком, тут не очень далеко». При этом нас совершенно не смущает то, что мы заранее не знаем, каков будет результат, наоборот — это дает нам большую гибкость и свободу действий; мы двигаемся дальше на основании того, каков был результат предыдущей операции. Подобно этому примеру, мы можем писать программы, которые оперируют переменными неопределенного типа. В результате, код получается более лаконичным, более читаемым и, в конце концов, более близким к естественному восприятию человека (ведь именно этого мы ждем от языков программирования!).
Концепция динамической типизации в полной мере нашла свое применение в языке Ruby. В этом языке любая переменная может в разное время иметь различные типы. Вот пример кода на этом языке:
<source lang=»ruby»>
def get_data(need_array = false)
result = 0 # целое число
if need_array
result = # тип меняется на Array
else
result = { 1 => 2, 3 => 4} # тип меняется на Hash
end
result
end
</source>
Преимущества динамической типизации:
- Легкость написания программ
- Лаконичность и хорошая читаемость
- Высокая гибкость языка. Возможность решения проблемы разными способами
- Большая возможность повторного использования кода (абстрактные алгоритмы)
Недостатки:
- Существенно меньшая производительность, по сравнению со статически типированными языками
- Сложность в написании оптимизаторов, их малая эффективность
- Как правило, динамически типированные языки являются интерпретаторами (компиляция не столь эффективна)
Вывод: Языки с динамической типизацией очень удобны для использования на прикладном уровне
Учитывая их высокую гибкость и лаконичность, программисту легче излагать свои мысли, при том, что свое внимание он концентрирует на самой задаче, не отвлекаясь на частные проблемы реализации. Конечно, они уступают по эффективности статическим, компилируемым языкам, однако это уже вопрос, требующий отдельного рассмотрения в рамках конкретно поставленной задачи.
Декларативное программирование
Декларативные языки программирования — это языки объявлений и построения структур.
К ним относятся функциональные и логические языки программирования.
В этих языках не производится алгоритмических действий явно, то есть алгоритм не задается прграммистом, а строится самой программой.
В декларативных языках задается, производится построение какой-либо структуры или системы,
то есть декларируются (объявляются) какие-то свойства создаваемого объекта.
Эти языки получили широкое применение в
1) системах автоматизированного проектирования (САПР),
2) в так называемых CAD-пакетах,
3) в моделировнии,
4) системах искусственного интеллекта
.
Типизация при инициализации
Более предпочтительным способом объявления типированной переменной является объявление с инициализацией. В данном случае, под инициализацией понимается процесс начального задания значения переменной. Для этого следует так же написать ключевое слово var, после которого сразу идет идентификатор имени переменной, а затем выражение — инициализатор, присваивающее значение вновь созданной переменной. При этом тип переменной будет определен как тип инициализатора:
<source lang=»kpp»>
var i = 0;
var s = «hello world»;
</source>
В приведенном выше примере, переменной i будет назначен целочисленный тип (), в то время как переменная s будет иметь строковый тип ().
Примечание: В некоторых случаях может сложиться ситуация, что инициализатор переменной это довольно сложное выражение. При этом программисту сложно определить, какой же на самом деле будет тип переменной. Для ясности приведем пример из разряда «как не надо делать»:
<source lang=»kpp»>
var x = 2+3*4+f(3)/3*0.2;
</source>
Синтаксически здесь все верно. Переменная будет создана и ей будет назначен некоторый тип. Но вот какой? Опытный читатель заметит, что в выражении присутствуют константы с плавающей точкой и операция деления. Стало быть, в результате приведения типов, результирующий тип переменной так же будет . Внимательный же читатель заметит так же, что в выражении присутствует f(3). И тут дело обстоит еще хуже. Функция может возвращать значение любого типа. Чтобы узнать какого именно, нужно обратиться к документации, либо к описанию самой функции. А что если она возвращает нетипированную переменную ()? Тогда предсказать тип переменной будет еще сложнее (если забежать вперед, то можно сказать что результат выражения так же будет нетипирован).
Скорее всего, Читатель уже согласился с мыслью, что подобных конструкций следует избегать. Однако что же делать, если все же требуется завести переменную, которая должна быть инициализирована подобным образом? Выхода тут может быть два. Либо отделить объявление переменной от ее инициализации, либо совместить типированное объявление с инициализацией.
Первый вариант:
<source lang=»kpp»>
var real x;
… //где то по коду программы
x = 2+3*4+f(3)/3*0.2;
</source>
Второй, более удачный вариант:
<source lang=»kpp»>
var real x = 2+3*4+f(3)/3*0.2;
</source>
Стоит отметить, что во втором случае будет выполнена операция приведения типов, то есть будет сделана попытка преобразовать тип значения инициализатора к явно указанному типу переменной. Если тип инициализатора возможно привести к типу переменной, то все пройдет успешно. Если же типы неприводимы, то произойдет либо ошибка компиляции (при статическом типе инициализатора), либо ошибка времени выполнения (при динамическом).

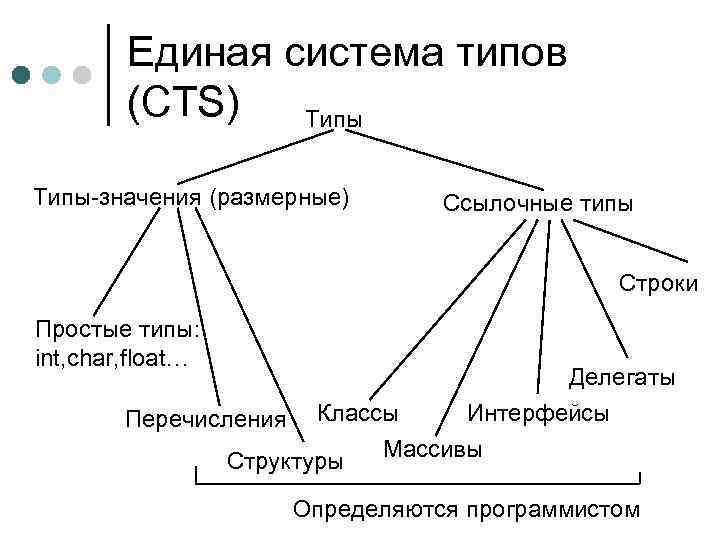

Специальные системы типов[править | править код]
Ряд специальных систем типов был разработан для использования в определённых условиях с определёнными данными, а также для статического анализа программ. В большинстве своём они основываются на идеях формальной теории типов и используются лишь в составе исследовательских систем.
Экзистенциальные типы
Экзистенциальные типы, то есть типы, определённые посредством экзистенциального квантификатора (квантора существования), представляют собой механизм инкапсуляции на уровне типов: это композитный тип, скрывающий реализацию некоего типа в своём составе.
Понятие экзистенциального типа часто используется совместно с понятием типа записи для представления модулей и абстрактных типов данных, что обусловлено их назначением — отделением реализации от интерфейса. Например, тип описывает интерфейс модуля (семейства модулей с одинаковой сигнатурой), имеющий в своём составе значение данных типа и функцию, принимающую параметр в точности этого же типа и возвращающую целое число. Реализация может быть различной:
Оба типа являются подтипами более общего экзистенциального типа и соответствуют конкретно реализованным типам, так что любое значение, принадлежащее любому из них, принадлежит также к типу . Если — значение типа , то проходит проверку типов, вне зависимости от того, к какому абстрактному типу принадлежит . Это даёт гибкость при выборе типов, подходящих для конкретной реализации, так как пользователи извне обращаются только к значениям интерфейсного (экзистенциального) типа и изолированы от этих вариаций.
В общем случае механизм проверки согласования типов не способен определить, к какому именно экзистенциальному типу принадлежит данный модуль. В примере выше также мог бы иметь тип . Простейшим решением является явное указание для каждого модуля подразумеваемого в нём типа, например:
intT = { a: int; f: (int → int); } as ∃X { a: X; f: (X → int); }
Хотя абстрактные типы данных и модули использовались в языках программирования довольно давно, формальная модель экзистенциальных типов была построена лишь к 1988 году. Теория представляет собой типизированное лямбда-исчисление второго порядка, аналогичное Системе F, но с экзистенциальной квантификацией вместо универсальной.
Экзистенциальные типы явным образом доступны в качестве экспериментального расширения языка Haskell, где они представляют собой специальный синтаксис, позволяющий использовать переменную типа в определении алгебраического типа, не вынося её в сигнатуру конструктора типов, то есть не повышая его арность. Язык Java предоставляет ограниченную форму экзистенциальных типов посредством джокера. В языках, реализующих классический в стиле ML, экзистенциальные типы могут быть симулированы посредством так называемых «значений, индексированных типами».
Модульное программирование
Мо́дульное программи́рование — это организация программы как совокупности небольших независимых блоков, называемых модулями.
Роль модулей могут играть структуры данных, библиотеки функций, классы, сервисы и др. программные единицы,
реализующие некоторую функциональность и предоставляющие интерфейс к ней.
Программный код часто разбивается на несколько файлов, каждый из которых компилируется отдельно от остальных.
Такая модульность программного кода позволяет значительно уменьшить время перекомпиляции при изменениях,
вносимых лишь в небольшое количество исходных файлов, и упрощает групповую разработку.
Термин «модуль» в программировании начал использоваться в связи с внедрением модульных принципов при создании программ.
В 1970-х годах под модулем понимали какую-либо процедуру или функцию, написанную в соответствии с определёнными правилами.
Например: «модуль должен быть простым, замкнутым (независимым), обозримым (от 50 до 100 строк),
реализующим только одну функцию задачи, имеющим одну входную и одну выходную точку».
Первым основные свойства программного модуля более-менее чётко сформулировал Д. Парнас (David Parnas) в 1972 году:
«Для написания одного модуля должно быть достаточно минимальных знаний о тексте другого».
Таким образом, в соответствии с определением, модулем могла быть любая отдельная процедура (функция)
как самого нижнего уровня иерархии (уровня реализации), так и самого верхнего уровня,
на котором происходят только вызовы других процедур-модулей.
Таким образом, Парнас первым выдвинул концепцию скрытия информации (англ. information hiding) в программировании.
Однако существовавшие в языках 70-х годов только такие синтаксические конструкции, как процедура и функция,
не могли обеспечить надёжного скрытия информации, из-за повсеместного применения глобальных переменных.
Решить эту проблему можно было только разработав новую синтаксическую конструкцию, которая не подвержена влиянию глобальных переменных.
Такая конструкция была создана и названа модулем.
Изначально предполагалось, что при реализации сложных программных комплексов модуль должен использоваться
наравне с процедурами и функциями как конструкция, объединяющая и надёжно скрывающая детали реализации определённой подзадачи.
Таким образом, количество модулей в комплексе должно определяться декомпозицией поставленной задачи на независимые подзадачи.
Впервые специализированная синтаксическая конструкция модуля была предложена Н. Виртом в 1975 г.
и включена в его новый язык Modula (а затем — Modula-2).
Минусы модульности: требуется большая аккуратность и больше времени на разработку. При выполнении требуется больше памяти.
Преимущества модульного программирования:
1) модули можно тестировать, отлаживать и поддерживать по отдельности;
2) можно повторно использовать модули из других проектов или купить их у сторонних производителей;
3) программу можно легче модернизировать простой заменой модулей.
Значение слова «типировать»

Делаем Карту слов лучше вместе
Я стал чуточку лучше понимать мир эмоций.
Вопрос: деторождение — это что-то нейтральное, положительное или отрицательное?
Предложения со словом «типировать»
Типы в этой типологии называются по сторонам света и типировать стало возможным не только людей, но и системы и явления.
Дополнительно
Предложения со словом «типировать»
Типы в этой типологии называются по сторонам света и типировать стало возможным не только людей, но и системы и явления.
Она позволяет типировать, то есть определять тип и описывать сложные процессы и явления нашего мира в модели, которую можно осознать и описать, используя при этом простые, но ёмкие по смыслу образы.
Политиков можно открыто типировать, поскольку от них зависит наша жизнь, и смешение личного и публичного – часть их профессионального риска.
Правописание
Карта слов и выражений русского языка
Онлайн-тезаурус с возможностью поиска ассоциаций, синонимов, контекстных связей и примеров предложений к словам и выражениям русского языка.
Справочная информация по склонению имён существительных и прилагательных, спряжению глаголов, а также морфемному строению слов.
Сайт оснащён мощной системой поиска с поддержкой русской морфологии.
Источник
Рекомендации экспертов и исследователей
Многие эксперты в области типирования людей считают, что важно помнить о том, что типирование не является окончательной категоризацией. Люди могут меняться, развиваться и претерпевать изменения в своих личностных характеристиках в зависимости от различных обстоятельств и ситуаций
Однако, типирование может быть полезным инструментом для более глубокого понимания себя и окружающих, а также способом улучшения взаимодействия и коммуникации с другими людьми.
Исследователи также рекомендуют не ограничиваться одним методом типирования, а использовать несколько для получения более полной картины своей личности и общения с другими
Важно помнить о том, что типирование не должно стать причиной для стереотипных оценок и предрассудков о других людях
- Изучайте различные методы типирования и выбирайте тот, который лучше всего подходит для вас;
- Оценивайте результаты типирования критически, не переоценивайте их значимость;
- Не используйте типирование как единственный способ понимания и оценки других людей;
- Не ограничивайте себя стереотипными представлениями о других людях на основе их типа личности;
Наконец, рекомендуется использовать результаты типирования в сочетании с другими источниками информации, такими как наблюдение, разговоры и общение с другими людьми, чтобы получить более полную картину личности человека и улучшить взаимодействия с ним.
Какой бывает
Рассматриваемая особенность бывает совершенно разной:
- слабой;
- сильной;
- явной;
- неявной;
- статической;
- динамической.
Далее каждый вариант будет рассмотрен более подробно
Особое внимание уделим последней «разновидности» на примере языка JS
Сильная и слабая
Это первый вариант классификации. Сильная типизация носит название строгой. Это значит, что разработчикам при создании программного кода потребуется придерживаться конкретных принципов работы с видами информации. Пример – если объект обозначен в виде целого числа, именно таким образом с ним предстоит «контактировать». На оный распространяются правила работы с целочисленными сведениями.
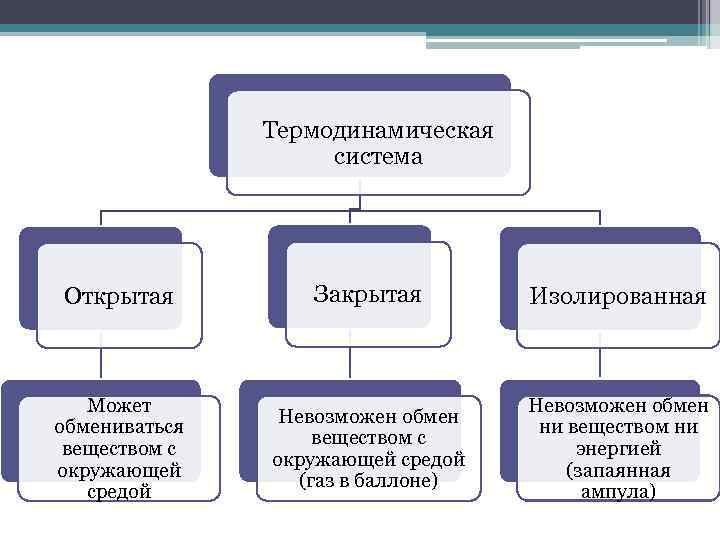

Языки со слабой типизацией «проще». В них можно сочетать разнообразные виды электронных материалов. Пример – прибавление к строке с текстом числового значения. При компиляции никаких ошибок на экране не будет. Но и результат на экране может оказаться совершенно не таким, каким его хочет видеть разработчик.
Статический вид
Статическая и динамическая типизация – еще один способ классификации рассматриваемой в статье особенности. Первый вариант предусматривает установку типа в процессе компиляции. Ошибки, которые могут возникнуть при обработке кода, видны до того, как программа будет запущена. Статически типизированные языки лучше «обнаруживают» неполадки.
Динамически типизированные языки будут определять тип задействованной информации во время работы приложения. Здесь стоит учесть, что:
- одна и та же переменная может рассматриваться кодификацией как разные типы в различных программных частях;
- статически типизированный вариант подобной возможности не имеет – строка всегда будет строкой, целое число – целым числом, булево значение – таковым.
Понимание соответствующих особенностей поможет разработчику максимально грамотно и эффективно создавать контент без ошибок.
Явные и неявные
А вот еще один способ классификации. Неявная типизация – это когда вид информации будет определяться непосредственно в момент записи сведений в переменные. Явный вариант предусматривает предопределение типа путем его записи.
Говоря простыми словами, в Python целое число задается так: x = 7, а в языке С: int x = 7.
Упомянутый способ разделения данных не слишком важно. Главное запомнить, что в статически типизированных языках почти всегда имеет место явный вариант, а в динамических – неявный