
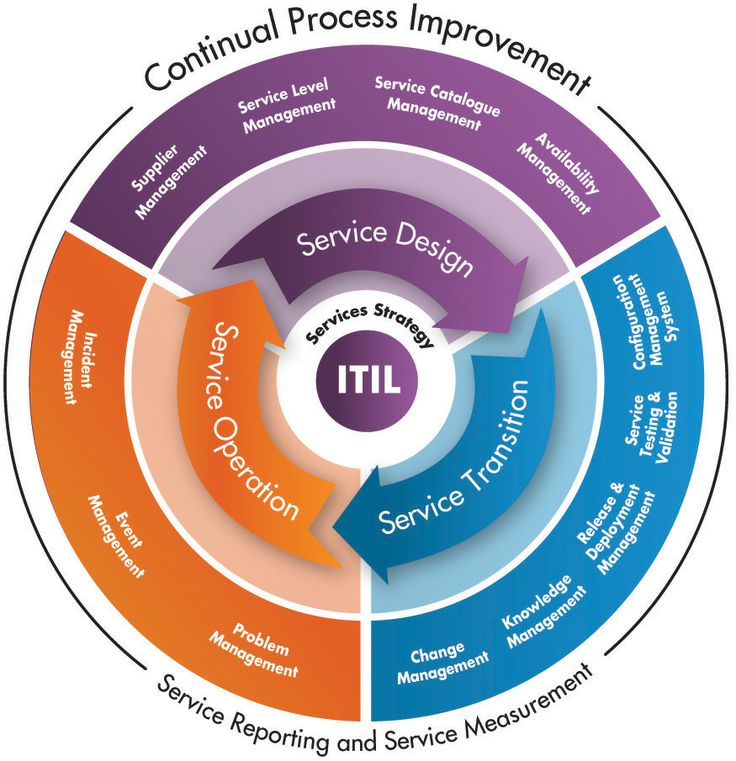
order() function in R
The R function returns a permutation of the order of the elements of a vector. The syntax with summarized descriptions of the arguments is as follows:
Note that the main difference between and is that the first it is designed for more than one vector of the same length. However, it is common to use the function with just one vector.
The output is an index vector that in this example means that if you want to sort the vector in ascending order, you have to put the fourth element first (14), then the third (25), then the first (34) and the greatest value is the second (47). If you set the argument to , you will have the vector of indices in descending order.
If the vector contains any values there will be at the end of the index vector by default.
In case you want the values to be displayed at the beginning you can set the argument to . Note that if you prefer removing the values, remember to call the or use some similar approach.
You can also use the function with a character vector. Note that ordering a categorical variable means ordering it in alphabetical order.
Как использовать сортировку по onid в телевизоре?
Для использования сортировки по onid в телевизоре, следуйте следующей инструкции:
1. Включите телевизор и перейдите в меню настроек.
Обычно кнопка доступа к меню настроек расположена на пульте дистанционного управления телевизора и имеет значок «Настройки» или «Menu». Нажмите эту кнопку, чтобы открыть меню настроек.
2. Найдите и выберите опцию «Сортировка каналов».
В меню настроек найдите пункт, связанный с сортировкой каналов. Имя этого пункта может варьироваться в зависимости от модели и производителя телевизора. Обычно это секция «Настройки каналов» или «Сортировка источников».
3. Выберите опцию «Сортировка по onid».
В списке доступных опций по сортировке выберите «Сортировка по onid». Это позволит активировать функцию сортировки каналов по идентификатору сети.
4. Нажмите кнопку «OK» или «Применить».
После выбора опции «Сортировка по onid», подтвердите свой выбор, нажав кнопку «OK» или «Применить». Это запустит процесс сортировки каналов по onid.
В зависимости от модели и производителя телевизора, вам может потребоваться выполнить дополнительные шаги или настройки, чтобы полностью включить и настроить сортировку по onid. Рекомендуется ознакомиться с инструкцией по эксплуатации вашей модели телевизора для получения подробной информации.
Что такое основание и разряд
Чтобы проще было вникнуть в материал, вспомним про основание чисел. Вот короткая версия:
- мы пользуемся десятичной системой счисления — это значит, что в основании этой системы стоит число 10;
- это значит, что, когда мы доходим до 9 и продолжаем увеличивать, девятка превращается в ноль, а мы добавляем единицу в следующий разряд;
- каждое число можно представить как сумму произведений из разрядов и числа 10 в нужной степени;
- например, 547 = 5×10² + 4×10¹ + 7×10⁰, где 10 — это основание системы счисления, а степени — порядковый номер числа справа налево, начиная с нуля. Этот порядковый номер и называется разрядом.
Страхование.
Страховые компании в течение ряда лет
накапливают большие объемы данных. Здесь обширное поле деятельности для методов
Data Mining:
·выявление
мошенничества. Страховые
компании могут снизить уровень мошенничества, отыскивая определенные стереотипы
в заявлениях о выплате страхового возмещения, характеризующих взаимоотношения
между юристами, врачами и заявителями.
·анализ
риска. Путем выявления
сочетаний факторов, связанных с оплаченными заявлениями, страховщики могут
уменьшить свои потери по обязательствам. Известен случай, когда в США крупная
страховая компания обнаружила, что суммы, выплаченные по заявлениям людей,
состоящих в браке, вдвое превышает суммы по заявлениям одиноких людей. Компания
отреагировала на это новое знание пересмотром своей общей политики
предоставления скидок семейным клиентам.
Что значит сортировка по onid
Экран основного меню включает 7 разделов:— каналы;— изображение;— поиск каналов;— время;— язык;— система;— USB.
Каналы
В этом подразделе доступно редактирование каналов, EPG (электронный программный гид),
сортировка по ID, ONID, LCN или названию канала, отдельное включение LCN (логический номер канала). В конкретном практическом примере при включенном LCN и выборе сортировки по нем, все каналы изменили свой номер на +800.
Возможно, что это будет не всегда удобно для зрителя.
Изображение
В данном подразделе выбираются пропорции экрана (в зависимости от экрана вашего телевизора и формата, в котором идет трансляция), разрешение (имеет значение при подключении через HDMI выход), формат ТВ – это выбор стандарта при подключении по аналоговому выходу. Если ваш телевизор поддерживает стандарт PAL, то рекомендуется выбрать именно этот стандарт из доступных PAL, SECAM, NTSC. Видео выход – выбор типа аналогового выхода CVBS или RGB. Для сигнала RGB (он более качественный) потребуется кабель полный SCART – SCART.Отдельно остановлюсь на выборе разрешения. Если ваш телевизор или монитор не поддерживает 1080р 50 Гц и вы случайно в приемнике выберете это разрешение, то картинка пропадет и для возвращения ее обратно потребуется кабель SCART – RCA, чтобы было видно как разрешение вернуть обратно. Можно попробовать и вслепую, если вы запомнили нужные позиции меню.Для выхода из настроек подменю нажать кнопку MENU на пульте ДУ и вновь станут доступны для выбора разделы меню.
Поиск каналов
Поиск каналов подробно рассматривался в разделе базовых настроек. В этом подменю дополнительно можно выбрать:— RF OUT – PAL-BG, PAL-I, PAL-DK, SECAM-DK, NTSC – это стандарты сигнала передаваемые приемником по радиочастотному выходу, здесь также рекомендуется выбирать PAL, если он поддерживается вашим телевизором. Буквы после наименования стандарта относятся к звуку. Выбрать стандарт PAL при котором вы получите на выходе изображение и звук.— RF канал, номер канала несущей частоты, доступны 21 – 69 каналы.
Время
В подменю можно настроить время для правильной работы EPG. Если местное время установлено в положение Авто, то часовой пояс будет взят по выбранному региону вещания, на примере Калининград (GMT + 3). Если местное время установить в положение Ручное, то часовой пояс выбирается вручную.Настройка Auto Standby определяет, через сколько времени приемник переключится в дежурный режим. Настройка Таймер позволяет в заданное время включить и выключить приемник.
Для выбора языка меню,субтитров, аудио. В настройке Цифровой звук доступны позиции Выкл., РСМ, RAW HDMI Вкл., RAW HDMI Выкл.
Язык
Для выбора языка меню,субтитров, аудио. В настройке Цифровой звук доступны позиции Выкл., РСМ, RAW HDMI Вкл., RAW HDMI Выкл.
Система
В этом подразделе меню доступны:— родительский контроль – установка возрастного ограничения на доступ к передачам (если такое ограничение транслируется в EPG), доступны 04 – 18 лет, заводской пароль к настройкам – 000000, полная блокировка доступа к каналу доступна в Редакторе каналов;— установить пароль – смена текущего пароля на свой;— сброс в заводские установки – для удаления всех текущих настроек и каналов;— информация;
USB
Для доступа и работы с подключенным USB накопителем. Более подробно подраздел рассмотрен в материалах о записи и воспроизведении мультимедийных файлов.









Материал предоставлен сайтом http://опенбокс.рф
QLED, ULED, Nano Cell и Triluminos — очередной развод маркетологов?

На самом деле квантовые точки — не только круто звучит, но и круто работает. Телевизоры с приставкой QLED, ULED, Nano Cell и Triluminos — это не просто переплата за очередное маркетинговое название, как можно было бы подумать, а действительно новая технология улучшения цвета, пусть и разработанная на базе старой доброй LED. Матрицы на квантовых точках дают намного более яркое и сочное изображение. Для светлого помещения или студии с большими окнами выбор в пользу таких моделей очевиден.
Телевизор на квантовых точках выручит и в том случае, если огромный черный прямоугольник не вписывается в новенький интерьер и идет вразрез с вашим дизайнерским вкусом. Именно эта технология лежит в основе большинства интерьерных моделей.
В бюджетном сегменте такие телевизоры не найти, ведь они считаются конкурентами самого OLED. В черном цвете они, конечно, ему уступают, но по яркости превосходят в разы.
Сортировка чисел по четности в Python
main.py
Данный код выполняет сортировку списка на основе четности чисел в нем с использованием функции и метода с ключом сортировки и аргументом для обратной сортировки.
Пояснение к коду:
— создание списка с данными числами.
— вызов метода на списке с ключом сортировки , что указывает на сортировку списка на основе остатка от деления чисел на 2. Таким образом, нечетные числа будут идти перед четными числами в порядке возрастания остатка от деления. Результат сортировки сохраняется в самом списке .
— вывод отсортированного списка на экран. Результат будет , так как числа отсортированы в порядке нечетных чисел перед четными числами.
— вызов функции с аргументом , ключом сортировки и аргументом , что указывает на сортировку списка на основе остатка от деления чисел на 2 в порядке убывания. Таким образом, четные числа будут идти перед нечетными числами. Результат сортировки сохраняется в переменной .
— вывод отсортированного списка на экран. Результат будет , так как числа отсортированы в порядке четных чисел перед нечетными числами с использованием функции .
Это только некоторые примеры кастомных сортировок, с помощью функций и можно реализовать множество других сортировок в зависимости от конкретной задачи.
Ограниченный контекст
- В каждом ограниченном контексте существует только один .
- Ограниченные контексты являются относительно небольшими, меньше чем может показаться на первый взгляд. достаточно велик только для единого языка изолированной предметной области, но не больше.
- Единый значит «вездесущий» или «повсеместный», т. е. язык, на котором говорят члены команды и на котором выражается отдельная модель предметной области, которую разрабатывает команда.
- Язык является единым только в рамках команды, работающей над проектом в едином ограниченном контексте.
- Попытка применить в рамках всего предприятия или что хуже, среди нескольких предприятий, закончится провалом.
Контекст банковских услугСводка о текущих счетах или сводка о сберегательных счетахЛитературный контекстНа сайте amazon.com продается книга Into Thin Air: A Personal Account of the Mt. Everest Disaster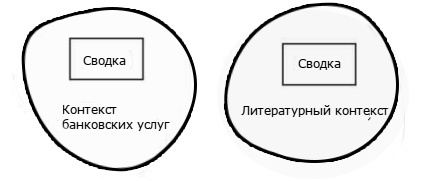
- Разработка концепции и предложения к изданию
- Контракт с автором
- Управление редакционным процессом
- Разработка макета книги, включая иллюстрации
- Перевод книги на другие языки
- Выпуск бумажных и/или электронных версий книги
- Маркетинг
- Продажа книги реализаторам и/или непосредственно покупателям
- Поставка экземпляров книги реализаторам или покупателям
Почему сортировка по ONID важна для пользователей
ONID (Oregon State University Network ID) — это уникальный идентификатор для студентов, сотрудников и выпускников университета Орегона. Использование сортировки по ONID является очень важным для пользователей, т.к. это позволяет быстро находить нужную информацию и упрощает работу в системе.
Сортировка по ONID позволяет сократить время поиска, так как при поиске любых данных, например, электронной почты, файлов, контактов, автоматически происходит фильтрация и подбор нужной информации. Таким образом, пользователи могут быстро и легко находить нужные файлы и прочие данные, предоставленные университетом.
Система сортировки по ONID предотвращает ошибки и повышает безопасность. Благодаря системе сортировки, пользователи могут избежать ошибок ввода важных данных, вроде адреса электронной почты или логина. Это позволяет избежать ошибок при обмене информацией с другими студентами и сотрудниками, а также повышает безопасность данных.
Сортировка по ONID позволяет лучше организовать свою работу. Задачи, проекты и другие мероприятия могут быть легко разделены на группы, в которых сортировка будет происходить по ONID. Так, пользователи могут с легкостью находить нужные материалы и коммуницировать с другими участниками проектов.
В заключении, использование сортировки по ONID является очень важным для пользователей, т.к. это позволяет быстро находить нужную информацию, предотвращает ошибки и повышает безопасность данных, а также позволяет более эффективно организовывать рабочий процесс.
Сортировка по onid: основные принципы
Сортировка по onid представляет собой один из важнейших алгоритмов сортировки коллекций элементов в программировании. Она основывается на сравнении уникальных идентификаторов (onid) каждого элемента и определении их относительного порядка.
Основные принципы сортировки по onid:
- Первым шагом необходимо присвоить каждому элементу уникальный идентификатор (onid). Для этого можно использовать целочисленные или строковые значения, либо какую-то комбинацию таких значений.
- Далее производится сравнение и сортировка элементов по их onid. Сравнение осуществляется в соответствии с заданными правилами, которые могут быть разными в зависимости от требований к сортировке.
- При сравнении onid двух элементов, определяется их относительный порядок: если onid первого элемента меньше onid второго элемента, то первый элемент будет располагаться перед вторым в отсортированной последовательности, и наоборот.
Пример сортировки по onid:
| Элемент | onid |
|---|---|
| Элемент 1 | 3 |
| Элемент 2 | 1 |
| Элемент 3 | 2 |
После сортировки элементы будут расположены следующим образом:
- Элемент 2
- Элемент 3
- Элемент 1
Здесь элементы отсортированы по возрастанию их onid: сначала идет элемент с наименьшим onid, затем с бОльшим, и так далее.
Сортировка по onid находит применение во множестве различных сфер программирования, от обработки данных до отображения результатов на веб-страницах. Ее использование позволяет эффективно структурировать и упорядочить информацию, что значительно упрощает поиск и манипуляции с элементами коллекций.
Что означает термин LCN
Рассматриваемый термин представляет собой аббревиатуру от сочетания Logical Channel Number, что означает логический номер канала. Включенная опция LCN в телевизоре означает, что весь найденный контент в перечне будет упорядочен по логике провайдера цифровых услуг. Поэтому у абонентов одного поставщика ЦТВ при активированной LCN сортировке перечень каналов идентичен. Технология сортировки Logical Channel Number выстраивает перечень в порядке возрастания 4-х значных номеров, присвоенных провайдером.
Регламентировать нумерацию каналов в полном объеме, которых вкупе с региональными и местными более 300, практически невозможно. Провайдеры распределяют телеконтент по номерам, исходя из своего видения рейтинга популярности.
О-нотация
Часто требуется оценить, сколько времени работает алгоритм. Но тут возникают проблемы:
- на разных компьютерах время работы всегда будет слегка отличаться;
- чтобы измерить время, придётся запустить сам алгоритм, но иногда приходится оценивать алгоритмы, требующие часы или даже дни работы.
Зачастую основной задачей программиста становится оптимизировать алгоритм, выполнение которого займёт тысячи лет, до какого-нибудь адекватного времени работы. Поэтому хотелось бы уметь предсказывать, сколько времени займёт выполнение алгоритма ещё до того, как мы его запустим.
Для этого сначала попробуем оценить число операций в алгоритме. Возникает вопрос: какие именно операции считать. Как один из вариантов — учитывать любые элементарные операции:
- арифметические операции с числами:
- сравнение чисел:
- присваивание:
При этом надо учитывать, как реализованы некоторые отдельные вещи в самом языке. Например, в питоне срезы массива () копируют этот массив, то есть этот срез работает за 7 элементарных действий. А , например, может работать за 3 присваивания.
Упражнение. Попробуйте посчитать точное число сравнений и присваиваний в сортировках пузырьком, выбором, вставками и подсчетом в худшем случае (это должна быть какая формула, зависящая от \(n\) — длины массива).
Чтобы учесть вообще все элементарные операции, ещё надо посчитать, например, сколько раз прибавилась единичка внутри цикла . А ещё, например, строчка — это тоже действие. Поэтому даже посчитав их, сразу очевидно, какой из этих алгоритмов работает быстрее — сравнивать формулы сложно. Хочется придумать способ упростить эти формулы так, чтобы:
- не нужно было учитывать много информации, не очень сильно влияющей на итоговое время;
- легко было оценивать время работы разных алгоритмов для больших чисел;
- легко было сравнивать алгоритмы на предмет того, какой из них лучше подходит для тех или иных входных данных.
Для этого придумали \(O\)-нотацию — асимптотическое время работы вместо точного (часто его ещё называют асимптотикой).
Определение. Пусть \(f(n)\) — это какая-то функция. Говорят, что алгоритм работает за \(O(f(n))\), если существует число \(C\), такое что алгоритм работает не более чем за \(C \cdot f(n)\) операций.
В таких обозначениях можно сказать, что
- сортировка пузырьком работает за \(O(n^2)\);
- сортировка выбором работает за \(O(n^2)\);
- сортировка вставками работает за \(O(n^2)\);
- сортировка подсчетом работает за \(O(n + m)\).
Это обозначение удобно тем, что оно короткое и понятное, а также оно не зависит от умножения на константу или прибавления константы. Например, если алгоритм работает за \(O(n^2)\), то это может значить, что он работает за \(n^2\), за \(n^2 + 3\), за \(\frac{n(n-1)}{2}\) или даже за \(1000 \cdot n^2 + 1\) действие. Главное — что функция ведет себя как \(n^2\), то есть при увеличении \(n\) (в данном случае это длина массива) он увеличивается как некоторая квадратичная функция. Например, если увеличить \(n\) в 10 раз, время работы программы увеличится приблизительно в 100 раз.
Все рассуждения про то, сколько операций в или считать ли отдельно присваивания, сравнения и циклы — отпадают. Каков бы ни был ответ на эти вопросы, они меняют ответ лишь на константу, а значит асимптотическое время работы алгоритма никак не меняется.
Первые три сортировки именно поэтому называют квадратичными — они работают за \(O(n^2)\). Сортировка подсчетом может работать намного быстрее — она работает за \(O(n + m)\), а если в задаче \(M \leq N\), то это вообще линейная функция \(O(n)\).
Упражнение. Найдите асимптотику данных функций, маскимально упростив ответ (например, до \(O(n)\), \(O(n^2)\) и т. д.):
- \(\frac{N}{3}\)
- \(\frac{N(N-1)(N-2)}{6}\)
- \(1 + 2 + 3 + \ldots + N\)
- \(1^2 + 2^2 + 3^2 + \ldots + N^2\)
- \(\log{N} + 3\)
- \(179\)
- \(10^{100}\)
Упражнение. Найдите асимптотическое время работы данных функций:
Упражнение. Найдите лучшее время работы алгоритмов, решающих данные задачи:
- Написать числа от \(1\) до \(n\).
- Написать все тройки чисел от \(1\) до \(n\).
- Найти разницу между максимумом и минимумом в массиве.
- Найти число единиц в бинарной записи числа \(n\).
Индекс должной осмотрительности в сервисе 1С:Парк Риски
Индекс должной осмотрительности — это специальный инструмент в сервисе 1С:Парк Риски, который позволяет оценить уровень рисков при работе с партнерами и клиентами.
Индекс должной осмотрительности рассчитывается на основе сложного алгоритма, учитывающего различные факторы, такие как финансовое состояние компании, наличие просроченных платежей и судебных дел, историю платежей и другие аспекты, которые могут влиять на стабильность и надежность партнеров.
Индекс должной осмотрительности представляется в виде числа от 0 до 100, где 0 — это максимально низкий риск, а 100 — максимально высокий риск. Чем ниже значение индекса, тем надежнее и безопаснее работать с партнером.
Оценка индекса должной осмотрительности осуществляется автоматически на основе данных, доступных в системе 1С:Парк Риски. Пользователь может посмотреть индекс для любого партнера или клиента и принять решение о дальнейшем сотрудничестве на основе этой информации.
Для удобства использования индекса должной осмотрительности в сервисе 1С:Парк Риски предусмотрена возможность фильтрации и сортировки партнеров по индексу. Также можно создавать отчеты и анализировать динамику изменения индекса для разных партнеров в течение определенного периода времени.
Индекс должной осмотрительности в сервисе 1С:Парк Риски помогает снизить возможные риски при ведении бизнеса и принимать обоснованные решения на основе надежных данных о партнерах и клиентах. Он является полезным инструментом для бухгалтеров, финансовых аналитиков и менеджеров по работе с клиентами.
Количество инверсий
Пусть у нас есть некоторая перестановка \(a\). Инверсией называется пара индексов \(i\) и \(j\) такая, что \(i < j\) и \(a > a\).


![Sort in r with sort() and order() functions 📝 [vectors, data frames, ...]](https://podomu.info/wp-content/uploads/2/1/3/213f12f6adccd86a8731c968c52e4859.png)




Очевидно, что эта задача легко решается обычным перебором двух индексов за \(O(n^2)\):
Внезапно эту задачу можно решить используя сортировку слиянием, слегка модифицируя её. Оставим ту же идею. Пусть мы умеем находить количество инверсий в массиве размера \(n\), научимся находить количество инверсий в массиве размера \(2n\).
Заметим, что мы уже знаем количество инверсий в левой половине и в правой половине массива. Осталось лишь посчитать число инверсий, где одно число лежит в левой половине, а второе в правой половине. Как же их посчитать?
Давайте подробнее рассмотрим операцию merge левой и правой половины (которую мы ранее заменили на вызов встроенной функции merge). Первый указатель указывает на элемент левой половины, второй указатель указывает на элемент второй половины, мы смотрим на минимум из них и этот указатель вдигаем вправо.
Рассмотрим число \(A\) в левой половине. В скольки инверсиях между половинами оно участвует? В стольки, сколько чисел в правой половине меньше, чем оно. Знаем ли мы это количество? Да! Ровно в тот момент, когда мы число \(A\) вносим в слитый массив, второй указатель указывает на первое число в правой половине, которое больше чем \(A\).
Значит в тот момент, когда мы добавляем число \(A\) из левой половины, к ответу достаточно прибавить индекс второго указателя (минус начало правой половины). Так мы учтем все инверсии между половинами.
Быстрая сортировка
Быстрая сортировка заключается в том, что на каждом шаге мы находим опорный элемент, все элементы, которые меньше его кидаем в левую часть, остальные в правую, а затем рекурсивно спускаемся в обе части.
Давайте оценим асимптотику данной сортировки. На случайных данных она работает за \(O(NlogN)\) , так как каждый раз мы будем делить массив на две примерно равные части, то есть суммарно размер рекурсии будет около логарифма и при этом на каждом этапе рекурсии мы просмотрим не более, чем размер массива. Однако можно легко найти две проблемы, одна — одинаковые числа, а вторая — если вдруг середина — минимум или максимум.
Существуют несколько выходов из этой ситуации :
-
Давайте если быстрая сортировка работает долго, то запустим любую другую сортировку за \(NlogN\).
-
Давайте делить массив не на две, а на три части(меньше, равны, больше).
-
Чтобы избавиться от проблемы с максимумом/минимумом в середине, давайте брать случайный элемент.
Поиск \(k\)-ой порядковой статистики за \(O(N)\)
Пусть дан массив \(A\) длиной \(N\) и пусть дано число \(K\). Задача заключается в том, чтобы найти в этом массиве \(K\)-ое по величине число, т.е. \(K\)-ую порядковую статистику.
Давайте поймем, что в быстрой сортировке мы можем узнать, сколько элементов меньше данного, тогда рассмотрим три случая
-
количество чисел, меньше данного = \(k — 1\), тогда наше число — ответ.
-
количество чисел, меньше данного >= \(k\), тогда спускаемся рекурсивно в левую часть и ищем там ответ.
-
количество чисел, меньше данного < \(k\), спускаемся в правую ищем (\(k\) — левая — 1) — ое число.
За сколько же это работает, из быстрой сортировки мы имеем, что размер убывает приблизительно в 2 раза, то есть мы имеем сумму \(\sum_{k=1}^n {2 ^ k} = {2^{k+1}-1}\) что в нашем случае это максимум равно \(2 * N — 1\), то есть \(O(N)\).
Также в C++ эта функция уже реализована и называется .
Что означает термин LCN
Рассматриваемый термин представляет собой аббревиатуру от сочетания Logical Channel Number, что означает логический номер канала. Включенная опцияLCN в телевизореозначает, что весь найденный контент в перечне будет упорядочен по логике провайдера цифровых услуг. Поэтому у абонентов одного поставщика ЦТВ при активированной LCN сортировке перечень каналов идентичен. Технология сортировки Logical Channel Number выстраивает перечень в порядке возрастания 4-х значных номеров, присвоенных провайдером.
Регламентировать нумерацию каналов в полном объеме, которых вкупе с региональными и местными более 300, практически невозможно. Провайдеры распределяют телеконтент по номерам, исходя из своего видения рейтинга популярности.
История и характеристик среды общих данных по ISO 19650
Среда общих данных определена международным стандартом ISO 19650, и определяется как «согласованный источник информации по конкретному проекту или активу, для сбора, управления и распространения наборов информации, посредством управляемого процесса». Ключевым тезисом в данном определении на мой взгляд является то, что среда общих данных устанавливает управление информацией через управляемый процесс. Из этого можно сделать вывод, что информации в среде общих данных присваивается определенное состояние процесса. И такую связь следует реализовать на техническом уровне. Именно поэтому стандарт ISO 19650 указывает также на то, что среда общих данных определяется в совокупности процессом и решением (solution), т.е. технической реализацией, которая эти процессы поддерживает. В стандарте определены основные состояния процесса среды общих данных: «в работе”, “в общем доступе”, “опубликовано” и “архив”. Кроме того для наборов информации определяются обозначение кодов версии и статусов разрешенного использования. Код версии в свою очередь предназначается для идентификации версии информационных наборов, а статус разрешенного использования информации определяет пригодность использования, т.е. для чего можно использовать информацию в текущем состоянии. Эта и сопутствующая информация размещается в согласованных метаданных информационных наборов. При этом с точки зрения концепции среды общих данных, состояние информации определяет и ее доступность: наборы информации, находящиеся в состоянии “В работе” доступны только для участников, которые эту информацию разрабатывают, в то время как “Опубликованная” информация доступна тем, кто эту информацию будет использовать по её назначению, как достоверную.
В итоге можно обозначить следующие основные характеристики СОД:
- централизованность — сведение в одном месте определенных данных и;
- управляемость – представление информации об этих данных в контексте их состояния управляемого процесса и представление связанных с этим свойств полноты информации, доступности, версионности и пригодности.
Сортировка по ONID: просто объясняем, что это
ONID (Online Numerical IDentifier) — это уникальный идентификатор, который используется на некоторых платформах для сортировки и поиска данных. Как правило, ONID выдается каждому пользователю при регистрации на сайте.
Сортировка по ONID может быть полезной, когда необходимо отобразить информацию, относящуюся к конкретному пользователю. Например, если вы администратор сайта и хотите просмотреть список всех пользователей, но при этом не хотите сортировать их по имени или электронной почте, то вы можете использовать сортировку по ONID.
Чтобы использовать сортировку по ONID, необходимо выбрать соответствующую опцию в настройках поиска или сортировки. Как правило, ONID отображается в виде числа или буквенно-числовой комбинации.
Пример использования сортировки по ONID:
- Зайдите на страницу «Пользователи» на сайте
- Выберите опцию «Сортировка по ONID»
- Пользователи будут отсортированы по уникальному идентификатору
Таким образом, сортировка по ONID — это удобный способ сгруппировать и отобразить информацию, связанную с конкретным пользователем. Она может быть полезна для администраторов, разработчиков и других пользователей, которые работают с большим объемом данных.
Сортировка строк по длине в Python
main.py
Данный код выполняет сортировку списка на основе длины строк в нем с использованием функции и метода с ключом сортировки и аргументом для обратной сортировки.
Пояснение к коду:
— создание списка с данными строками.
— вызов метода на списке с ключом сортировки , что указывает на сортировку списка на основе длины строк в порядке возрастания. Результат сортировки сохраняется в самом списке .
— вывод отсортированного списка strings на экран. Результат будет , так как строки отсортированы в порядке возрастания длины.
— вызов функции с аргументом , ключом сортировки и аргументом , что указывает на сортировку списка на основе длины строк в порядке убывания. Результат сортировки сохраняется в переменной .
— вывод отсортированного списка на экран. Результат будет , так как строки отсортированы в порядке убывания длины с использованием функции .
Что такое метод sort() в Python?
Этот метод берет список и сортирует его. То есть на выходе мы получаем тот же список, только отсортированный. Этот метод не возвращает никакого значения.
В этом примере у нас есть список чисел, и мы можем использовать метод для сортировки списка в порядке возрастания.
my_list =
# Выводим неупорядоченный список:
print("Unordered list: ", my_list)
# Сортировка списка
my_list.sort()
# Выводим упорядоченный список
print("Ordered list: ", my_list)
Выполним наш код и получим следующий результат:
Unordered list: Ordered list:
Однако если список уже отсортирован, то мы получим None.
my_list = # Это строка вернет None, потому что список уже отсортирован print(my_list.sort())
Метод может принимать два необязательных аргумента: и .
Значением выступает функция, которая будет вызываться для каждого элемента в списке.
От редакции Pythonist. О функциях и их аргументах у нас есть отдельная статья — «Функции и их аргументы в Python 3».
В следующем примере давайте используем функцию в качестве значения аргумента key. Таким образом, скажет компьютеру отсортировать список имен по длине, от наименьшего к наибольшему.
names =
print("Unsorted: ", names)
names.sort(key=len)
print("Sorted: ", names)
Вот, что мы получим:
Unsorted: Sorted:
Аргумент может иметь логическое значение: (Истина) или (Ложь).
В следующем примере укажет компьютеру отсортировать список в обратном алфавитном порядке.
names =
print("Unsorted: ", names)
names.sort(reverse=True)
print("Sorted: ", names)
# Результат:
# Unsorted:
# Sorted:
Сортировка строк[править | править код]
Одним из частых приложений алгоритмов сортировки является сортировка строк. Обобщенный алгоритм может выглядеть так: сначала множество строк сортируется по первому символу каждой строки, затем каждое подмножество строк, имеющих одинаковый первый символ, сортируется по второму символу, и так до тех пор, пока все строки не будут упорядочены. При этом отсутствующий символ (при сравнении строки длины N со строкой длины N+1) считается меньше любого символа.
Применение данного метода к строкам, представляющим собой числа в естественной записи, выдаёт контринтуитивные результаты: например, «9» оказывается больше, чем «11», так как первый символ первой строки имеет бо́льшее значение, чем первый символ второй. Для исправления этой проблемы алгоритм сортировки может преобразовывать сортируемые строки в числа и сортировать их как числа. Такой алгоритм называется «числовой сортировкой», а описанный ранее — «строковой сортировкой». Также на практике эффективным способом решения проблемы сортировки строк, содержащих числа, является добавление некоторого числа нулей перед числом, таким образом, «011» будет считаться больше «009».
Достоинства цифрового ТВ
Мы уже поговорили немного о том, чем цифровое телевидение отличается от аналогового. Почти все, что было сказано, описывало преимущества современного метода передачи данных. О чем мы не сказали, так это о простоте передачи сигнала от телевизионной компании к пользователю.







Цифровое ТВ не нуждается в отдельных линиях передачи данных в виде проводов. Нужна антенна, которая подключается к телевизору, приемник цифрового формата, ну и источник питания в виде розетки, куда все это дело будет подключаться.

Приставку можно брать с собой в дорогу, и подключать в любом подходящем месте – уровень изображения от этого страдать не будет.


OLED — лучший!=”subtitle”>

У органических диодов множество преимуществ, о которых маркетологи прожужжали нам все уши: и бесконечная контрастность, и глубокий черный цвет, и сочное изображение. Однако не стоит забывать о недостатках. Во-первых, это выгорание статичной картинки в виде логотипа любимого канала, а при использовании телевизора в качестве монитора — интерфейса игры или операционной системы. Впрочем, работы над решением проблемы ведутся…
Во-вторых, великолепный и насыщенный OLED часто выглядит слишком нереально, что может отпугнуть любителей естественного изображения.
World Vision Premium — наиболее часто задаваемые вопросы и ответы на них:
Комбинированная эфирная, цифровая, DVB T2/C приставка для приема цифрового телевидения в стандартах эфирного DVB-T2 и кабельного DVB-C телевидения. 2 USB порта. Мультимедиа. Интернет приложения (Погода, RSS Чтение, YouTube, Gmail, IPTV, Megogo) через WI FI (поддержка беспроводных Wi-Fi адаптеров на чипе Ralink RT5370 и Mediatek MT7601). Подержка Dolby Digital. Передняя панель с цифровым дисплеем и кнопками управления POWER, MENU, CH+/-. Подключение к телевизору через RF LOOP, HDMI, RCA. Качественная программная поддержка (постоянно выходят новые прошивки). Бесплатные списки IPTV в нашем файловом архиве.
Вопрос: На экране ТВ постоянно сообщение «Перегрузка антенны по питанию», как выключить данное сообщение? Ответ: Требуется перейти в Меню — Установка — Настройка антенны — Питание на антенну (5V ) — установить в состояние Выкл.
Телекоммуникации.
В области телекоммуникаций методы Data Mining помогают компаниям
более энергично продвигать свои программы маркетинга и ценообразования, чтобы
удерживать существующих клиентов и привлекать новых. Среди типичных мероприятий
отметим следующие:
·анализ
записей о подробных характеристиках вызовов. Назначение такого анализа — выявление категорий клиентов
с похожими стереотипами пользования их услугами и разработка привлекательных
наборов цен и услуг;
·выявление
лояльности клиентов. Data Mining можно использовать
для определения характеристик клиентов, которые, один раз воспользовавшись
услугами данной компании, с большой долей вероятности останутся ей верными. В
итоге средства, выделяемые на маркетинг, можно тратить там, где отдача больше
всего.
Заключение
В этой статье мы разобрали, как работает сортировка списков в Python. Узнали, как работать с такими методами, как и , и в чем их различия.
Метод работает только со списками и сортирует уже имеющийся список. Данный метод ничего не возвращает.
А метод работает с любыми итерируемыми объектами и возвращает новый отсортированный список. В качестве итерируемых объектов могут выступать списки, строки, кортежи и другие.
У обоих этих методов есть два необязательных аргумента: и .
Значением аргумента может быть функция. Она будет вызываться для каждого элемента в списке. По этой функции, собственно, и будет проводиться сортировка.
Значением аргумента может быть или .
Надеемся, эта статья была для вас полезна. Успехов в написании кода!
Перевод статьи «Python Sort List – How to Order By Descending or Ascending».