
main
Тег <main> — это семантический тег, введенный в HTML5. Он используется для разметки основного содержимого веб-страницы, которое обычно является центральным или наиболее важным контентом, имеющим отношение к теме или назначению страницы.
Тег <main> следует использовать только один раз на странице, и он не должен содержать никакого содержимого, которое не является частью основного содержимого страницы. Тег следует использовать для переноса основного содержимого страницы, такого как статьи, разделы или другой важный контент.
В этом примере тег <main> используется для переноса тегов <article> и <section>, которые содержат основное содержимое страницы. Это обеспечивает дополнительный контекст для поисковых систем, помогая улучшить доступность сайта поисковых системах.
Дополнительные семантические элементы
В дополнение к обычно используемым семантическим тегам, существует несколько других семантических тегов, которые можно использовать для структурирования содержимого веб-страницы. Вот некоторые другие семантические теги и их назначение:
Определяет набор навигационных ссылок
Определяет контент, который связан с основным контентом, но не является его неотъемлемой частью
и : Эти теги используются для группировки изображений с соответствующими подписями. Тег используется для размещения изображения, в то время как тег используется для размещения подписи.
: Этот тег используется для обозначения дат, времени и продолжительности способом, который является машиночитаемым и легко понятным для людей.
: Этот тег используется для обозначения контактной информации, такой как физический адрес, адрес электронной почты и номер телефона компании или частного лица.
и : эти теги используются для создания сворачиваемых разделов содержимого
Тег используется для размещения содержимого, в то время как тег используется для предоставления краткого описания или заголовка содержимого.
: Этот тег используется для выделения текста, обычно с целью привлечения внимания к важной информации или поисковым запросам.
: Этот тег используется для отображения хода выполнения задачи, такой как загрузка файла или отправка формы.
: Этот тег используется для отображения результатов измерения, таких как ход кампании по сбору средств или уровень заряда батареи устройства.
Это всего лишь несколько примеров многих других семантических тегов, доступных в HTML. Используя эти теги надлежащим образом, вы можете создавать более структурированные и доступные веб-страницы, которые легче понять как людям, так и поисковым роботам.
Преимущества использования семантических элементов
Использование семантических HTML-элементов может принести пользу вашему сайту многими способами:
Улучшенная доступность веб-сайта — предоставляя контекстную информацию о содержимом, семантические HTML-элементы облегчают для программ чтения с экрана навигацию и понимание структуры веб-страницы
Это повышает доступность веб-сайта для пользователей с ограниченными возможностями.
Лучшая поисковая оптимизация — поисковые системы используют семантические HTML-элементы для определения релевантности и важности контента. Используя семантический HTML, вы можете улучшить SEO вашего сайта и повысить его видимость в результатах поиска.
Более чистый и поддерживаемый код — семантические HTML-элементы делают код более читаемым и простым в поддержке
Четко указывая назначение каждого элемента, становится легче обновлять и модифицировать код в будущем.
Последовательность и ясность — использование семантических HTML-элементов делает веб-сайт более последовательным и понятным. Следуя стандартной структуре, пользователи могут быстро определить назначение каждого раздела и более эффективно перемещаться по веб-сайту.
Заключение
Семантические HTML-элементы являются важным инструментом для веб-разработчиков для создания значимых и доступных веб-страниц. Предоставляя контекстную информацию о контенте, семантические HTML-элементы могут улучшить доступность веб-сайта, SEO и читаемость кода. Используя семантические HTML-элементы, вы можете создать более согласованный и удобный веб-сайт, который обеспечивает лучший пользовательский опыт.
Какие ошибки можно допустить при сборе семантического ядра
Составлять семантику, не учитывая особенности компании. Например, применять сочетание «покупка микроволновки с доставкой», если вы не доставляете технику.
Учитывать только высокочастотные запросы. По ним придётся конкурировать с большим числом площадок. Начинайте работу по продвижению недавно созданных ресурсов со средне- и низкочастотных запросов, а потом добавляйте высокочастотные. В дальнейшем ориентируйтесь на все три вида частотности.
Забывать об информационных запросах. Если использовать только коммерческие, можно потерять часть заинтересованной аудитории.
Анализировать только общую частотность. Необходимо учитывать также точную и фразовую, а ещё сезонность бизнеса.
Для сезонного бизнеса собирайте поисковые запросы в период, когда товары и услуги продаются активнее всего. Так получится составить полный список словосочетаний и не пропустить часть из них.
Однако также необходимо собирать частотность и в другие периоды, чтобы прогнозировать объём трафика и продаж на это время.
Семантическое ядро в структуре сайта
Есть два подхода — построить сайт на собранной семантике и собрать семантику для уже существующей структуры. Распределение СЯ по готовому каркасу — это результат вашего видения работы с пользователями, а организация сайта исходя из запросов будет ответом на текущую ситуацию в их поведении.
Даже если накладывать СЯ на готовую структуру, ее все равно, скорее всего, придется корректировать — убирать дублирующиеся по семантике страницы, пересобирать какие-то из разделов, создавать новые. В любом случае проанализировать семантику полезно, чтобы понять, получают ли пользователи нужную информацию.
В идеальной ситуации структуру сайта строят на готовой семантике. Такой сайт не будет вступать в противоречие с логикой пользователя
Это одинаково важно и при первичной, и при функциональной навигации
Цель первичной навигации — возвращение пользователя для покупки или получения информации. Функциональной навигацией называют прохождение этапов выбора, покупки и оплаты товара или подписки на персональные предложения.
Например, сайт по изготовлению сувениров можно спроектировать так:
| Название раздела | Содержание раздела |
|---|---|
| Главная страница | Краткое описание компанииВидео или изображения с процессом изготовления сувенировОсновные категории продукции |
| Каталог товаров | Разделение на категории — магниты, кружки, футболкиФильтры для удобства поиска — по типу сувенира, цене, материалуОписания и изображения каждого товара |
| О нас | История или миссия компанииОписание производственного процессаКоманда сотрудников |
| Как заказать | Информация о процедуре заказаОпции настройки сувениров — размер, цвет, нанесение логотипаИнструкции по оплате и доставке |
| Портфолио | Фотографии готовых сувенировОтзывы клиентовПримеры заказов для корпоративных клиентов |
| Блог | Статьи о том, как выбрать сувенир, идеи для подарков и другие тематические материалыНовости компании и обновления в ассортименте |
| Контакты | Форма обратной связиКонтактная информация |
| FAQ | Часто задаваемые вопросы |
| Политика конфиденциальности и условия использования | Информация о том, как обрабатываются данные клиентов, и правила использования сайта |
| Подписка на новости | Форма подписки на рассылку |
Сервисы для парсинга и кластеризации семантического ядра
Для сбора и кластеризации семантики есть много платных и бесплатных инструментов. Мы уже упоминали несколько сервисов и сейчас остановимся на них подробнее.
Key Collector
Автоматизированный сервис для подбора семантического ядра. Умеет собирать ключи через «Яндекс.Вордстат», парсить поисковые подсказки, выгружать данные с Google Ads и сервисов аналитики, чистить семантику от стоп-слов, дублей и сезонных запросов, делать фильтрацию по частотности. Частотность Key Collector собирает в Yandex Direct, Google Ads, LiveInternet, Rambler Adstat и APIShop.com.
Главные достоинства Key Collector — разнообразные источники парсинга, большая глубина сбора, возможность группировки собранной базы. Из минусов SEO специалисты отмечают медленную работу, особенно при увеличенной глубине сбора, и необходимость покупки антикапч.
Интерфейс Key Collector
Программа платная, работает по лицензии. Стоимость лицензии зависит от статуса покупателя: физическому лицу бессрочная лицензия обойдется в 2 200 рублей, организации придется заплатить 2 300 рублей.
MOAB.Tools Семантика
Это онлайн-сервис, который парсит до четырех миллионов фраз в час и собирает для семантического ядра запросы из Wordstat и подсказок, в том числе запросы с длинным полным хвостом спецификаторов. При поиске нет проблем с капчей, можно выбрать регионы, найти ультранизкочастотные запросы и интегрировать результат с Key Collector. Удобно, что сервис сразу проверяет частотность.
Работа парсера MOAB.Tools
Инструмент платный, но в тарифе Free первые 5 000 фраз можно собрать бесплатно. Тариф Mini стоит 1 299 рублей и рассчитан на ядро до 50 000 фраз. Для крупных проектов разработан тариф Pro, с которым за 6 099 рублей можно найти до 500 000 фраз.
«Словоеб»
Сервис позиционируется как бесплатная альтернатива Key Collector. У программы похожий интерфейс и принцип работы, но возможности парсинга ограничены результатами «Вордстат», Rambler.Adstat и поисковыми подсказками «Яндекс» и Google. Частотность фраз программа тоже проверяет только по «Вордстат».











Работа программы «Словоеб»
По сути, «Словоеб» выполняет базовую работу по сбору семантики в «Яндекс.Вордстат», но в автоматическом режиме. За 10-15 минут он собирает несколько тысяч запросов, что в разы быстрей ручного сбора.
Yandex Wordstat Assistant
Браузерное расширение для упрощения работы с «Вордстат». Бесплатный сервис, который копирует и сохраняет ключевые слова из «Яндекс.Вордстат» в таблицы Excel. Умеет сортировать запросы по частотности, алфавиту или порядку добавления. Автоматически ищет дубли и позволяет добавлять ключи вручную.
Составление семантического ядра с помощью браузерного расширения
Расширение бесплатное, устанавливается для Google Chrome, Opera, Mozilla Firefox и «Яндекс.Браузер».
Serpstat
Мультиинструментальный сервис для работы с семантическим ядром, кластеризации и SEO анализа.

Интерфейс сервиса Serpstat
При сборе семантики учитывает частотность и конкурентность запросов по шкале от 1 до 100, показывает сложность продвижения. Может работать с региональной выдачей и сравнивать результаты с сайтами конкурентов. Особенно удобно, что Serpstat группирует ключевые слова по страницам и рекламным кампаниям с учетом однородности.
У сервиса есть бесплатная версия с ограниченным функционалом. Подписки оформляются на месяц или год. Самая недорогая стоит 55$ в месяц.
Rush Analytics
Сервис автоматизации парсинга и кластеризации семантического ядра. Собирает запросы и показывает их частотность на основе данных «Яндекс.Вордстат» и Google Ads, ищет подсказки в «Яндекс», Google и YouTube. Умеет кластеризовать ключевые слова методом Soft и Hard, автоматически создает структуру сайта.

Интерфейс Rush Analytics
Бесплатная версия с ограниченным функционалом доступна семь дней. Минимальный тариф стоит 500 рублей в месяц.
Готовое ядро выглядит как электронная таблица, где по каждой ключевой фразе указана базовая (по всем вариантам использования ключевого слова) и точная (без словоформ) частотность, а для каждого кластера — продвигаемая страница.
Данные в таком формате можно сразу использовать для SEO и контекстной рекламы:
- Разрабатывать или оптимизировать структуру сайта.
- Отбирать перспективные запросы с низкой стоимостью клика и запускать контекстную рекламу с дешевым целевым трафиком.
- Составлять контент-план на несколько лет или месяцев.
- Делать технические задания для контентного наполнения или оптимизации текущего контента.
Как сделать ваш контент насыщенным семантикой
Вот несколько стратегий, позволяющих применить теорию на практике и оптимизировать сайт для семантического поиска:
Играйте с алгоритмами
Поисковые системы постоянно совершенствуют свои алгоритмы и совершенствуют свои методы для определения релевантного контента и повышения качества обслуживания пользователей поисковых систем. Когда поисковые системы ранжируют контент, они учитывают такие вещи, как голосовые запросы, богатую поисковую информацию, такую как мета- и избранные фрагменты, время загрузки страницы и т. д.
Кроме того, раньше Google представила новый способ для своих алгоритмов идентифицировать и классифицировать соответствующий контент с помощью «Графика знаний». График знаний использует семантический поиск для понимания контекста вашего контента и помогает пользователям находить информацию на основе ключевых слов, связанных поисковых слов и вопросов. Это также один из способов для Google отвечать на поисковые запросы непосредственно на страницах поисковой системы.
Переключиться на тематическое исследование
Многие авторы контента все еще совершают ошибку, используя расширенные ключевые слова, чтобы повысить рейтинг своего контента. Однако сканеры поисковых систем теперь ранжируют контент, понимая лежащий в его основе контекст, поэтому маркетологам и авторам контента необходимо использовать семантический поиск.
Это означает, что вы должны тщательно изучать тему своего контента и намерения пользователей. Что ищет читатель? Какие решения они пытаются найти? Они ищут ответы или дополнительную информацию по теме?
Сделайте свой контент более разговорным
Голосовой поиск — это поисковый запрос, который пользователи используют, произнося свои вопросы, а не печатая их, например, с помощью ИИ-помощника. Это более удобный способ поиска запросов, поскольку он не требует хлопот с вводом текста, но он также более неформален, что создает новые проблемы для SEO. Голосовой поиск также получает много локальных запросов, поэтому оптимизация вашего контента для соответствующих географических местоположений также может помочь в этом отношении.
Вот почему так важно, чтобы содержание вашей статьи имело разговорный тон и было оптимизировано для определенных ключевых слов. Учитывая, что половина поисковых запросов осуществляется голосом, статьи должны иметь один простой вопрос в начале статьи, чтобы сканеры поисковых систем могли идентифицировать ваш контент как релевантный
Включите структурированные данные в свой контент
Структурированные данные представлены в виде графиков, таблиц, метатекста и т. д., чтобы предоставить поисковым системам дополнительную, более подробную информацию о вашем контенте. Это помогает поисковым системам классифицировать ваши статьи, делая их доступными для целевой аудитории. Этот тип структурирования также может помочь оптимизировать ваш сайт, чтобы сократить время загрузки страниц , сделать ваш сайт более доступным и т. д.
Например, если ваш блог посвящен книге по маркетингу, в ваши структурированные данные можно добавить мета-описание из шестидесяти слов об авторе книги и краткое описание книги, которое может помочь Яндекс и Google ранжировать ваш контент в верхней части поисковой выдачи.
Семантика: основные принципы и примеры
Семантика – это раздел лингвистики, который изучает значение слов, предложений и текстов, а также их взаимосвязь и использование в коммуникации.
Основными принципами семантики являются:
- Арбитрарность знака – каждое слово представляет собой произвольное звуковое обозначение, связанное с определенным значением и условно согласованное с общепринятыми правилами языка.
- Композициональность – значение предложения или текста возникает в результате комбинирования значений его составляющих слов.
- Контекстуальность – значение слова зависит от контекста, в котором оно употребляется. Одно и то же слово может иметь различные значения в разных ситуациях.
- Полиризация – некоторые слова обладают несколькими значениями, которые могут быть противоположными или синонимичными в зависимости от контекста. Например, слово «замечательный» может означать и положительное и отрицательное качество.
- Синонимия – семантическое совпадение двух или более слов в определенном контексте. Синонимы могут иметь частичное или полное совпадение значения.
- Антонимия – противоположность в значениях двух или более слов. Антонимы могут быть градационными (например, «холодный» – «теплый») или полными (например, «черный» – «белый»).
Ниже приведены примеры прототипических семантических отношений:
- Гиперонимия – отношение «является частью», например, «роза» является гиперонимом для «цветок».
- Гипонимия – отношение «является видом», например, «красный» является гипонимом для «цвет».
- Синтагматические отношения – связи между словами в рамках предложения или текста, например, «кот ловит мышь».
- Парадигматические отношения – связи между словами, которые могут заменять друг друга в определенном контексте, например, «кушать» – «есть», «ходить» – «идти».
- Антонимические отношения – противоположность в значениях, например, «большой» – «маленький».
В семантике также изучаются лексические и грамматические значения слов, значения словосочетаний и контекстуальные значения, что позволяет понять сложности и многообразие значений, которые содержатся в языках.
Знание семантики помогает нам осознать истинное значение слов и использовать их правильно в различных ситуациях общения, улучшая наши навыки в общении и понимании других людей.
Пример актуализации семантики
Небольшой агрегатор образовательных курсов. Спустя полгода после начала индексации сайта трафик из поиска практически отсутствовал несмотря на качество контента и технические характеристики сайта.
Анализ показал, что структура сайта не соответствует актуальному семантическому графу, и основные категории не имеют необходимых вспомогательных узлов.
После подготовки рекомендаций владелец сайта существенно масштабировал структуру разделов, добавив необходимые для ранжирования подкатегории. В результате этого удалось практически сразу значительно увеличить трафик из поиска, фактически не добавляя ничего, кроме новых теговых страниц.










Как собрать мультирегиональное семантическое ядро?
Создание семантического ядра под несколько регионов содержит определенные нюансы и есть несколько методов как это реализовать. Приведу наиболее популярные:
Метод поддоменов и подпапок
Если ваша компания имеет представительства, к примеру, в трех городах, а поисковая выдача по каждому городу сильно отличается — рекомендую создать поддомены (или подпапки) и под каждый из них собрать семантическое ядро отдельно:
https://moskava.mywebsite.com/ — поддоменыhttps://spb.mywebsite.com/https://ufa.mywebsite.com/
https://mywebsite.com/moskva/ — подпапкиhttps://mywebsite.com/spb/https://mywebsite.com/ufa/
Метод создания поддоменов под каждый регион является дорогостоящим, так как для каждого поддомена нужен отдельный контент, но это один из самых эффективных методов в продвижении мультирегионального сайта. Каждый поддомен вы сможете напрямую присвоить отдельному региону в Панели Вебмастера. Яндекс хорошо ранжирует поддомены и . Плюс рекомендую прочитать блог Яндекса — «Региональность: вопросы и ответы».
В качестве альтернативного решения, можно создавать не поддомены, а подпапки — внутренние разделы сайта. Их можно быстро создать, но во-первых, они тоже требуют отдельного контента, а во-вторых, их не получится так легко присвоить отдельному региону, как в случае с поддоменами. Придется подождать, пока поисковик проанализирует структуру и начнет доверять сайту.
Метод топонимов
Если у вас много регионов продвижения и при этом ограниченный бюджет, а сама поисковая выдача не сильно отличается — можете использовать метод топонимов. Достаточно собрать всю семантику по центральному региону, например Москва, а потом для каждого ключевого слова подставить в конце нужный топоним:
«разработка сайтов» + «топоним»
Виды ключевых слов
Подбирая ключевые слова, SEO-специалист учитывает:
- частотность – количество запросов в месяц;
- тип – показывает, какое намерение пользователя скрывается за определенной фразой.
При этом важно учитывать возраст сайта, степень его наполненности контентом и пр
Виды ключей по частотности:
- ВЧ – высокочастотные. К этой группе относятся фразы и слова, которые пользователи ежемесячно вводят в поисковую строку более 1 500 раз.
- СЧ – среднечастотные. Запрос этого типа пользователи ищут менее 1 500 раз в месяц, но более 500.
- НЧ – низкочастотные запросы. Количество запросов в месяц для этой категории не превышает 500.

Для молодых сайтов подходит стратегия – выписывать страницы по низкочастотным ключам. По ним легче продвигаться, а конкуренция в большинстве случаев низкая.
Плюсом низкочастотных ключей является наличие «скрытых», смежных интентов (смыслов). К примеру, пользователь ищет инструкцию по установке раковины в ванной. Дополнительно вводить и запросы про инструменты «для установки раковины»
По типу ключевые слова объединяют в следующие группы:
- Информационные. К ним относятся в основном запросы, направленные на поиск сведений – «как испечь торт» или «какой макияж выбрать», «что такое КПП».
- Коммерческие. Включают такие слова, как «купить», «заказать», «стоимость», «цена», «с доставкой». Еще эти запросы называют транзакционными, поскольку пользователь намерен совершить действие – транзакцию.
- Брендовые. В них включено название бренда. По таким запросам в топе всегда находятся компании, чей бренд продвигается.
- Геозависимые и геонезависимые. Ключи могут содержать название города – в таком случае они привязываются к региону. Пользователь быстрее найдет сайт, оптимизированный под конкретный город или область.
- Другие, общие запросы. Пользователи часто вводят в поисковую строку довольно широкие фразы, по которым сложно понять намерение. К примеру, запрос «пирог» может быть связан с желанием приготовить выпечку или купить его в магазине.
В отдельную группу выделяют навигационные запросы. По ним аудитория ищет конкретный сайт. Если ключи неспецифичны для бизнеса или ниши, их игнорируют.
Парадигматика и синтагматика в семантике
Семантика описывает семантические отношения с двух точек зрения: парадигматической и синтагматической.
Парадигматика занимается группировкой в языковой системе слов по принципу оппозиции (синонимия, антонимия, паронимия и др.). Наиболее общей группировкой слов является поле, которое может быть двумя основными видами:
- предметное поле – группировка слов по их отношению к одной предметной сфере (например, наименование растений, животных), организованная преимущественно по принципу «пространство»;
- понятийное поле – группировка слов по их отношению к одной понятийной сфере (например, обозначение душевных и ментальных состояний), организованная преимущественно по принципу «время».
Семантические отношения в парадигматике формализуются через механизм математической теории множеств.
Синтагматика занимается группировкой в языковой системе слов по принципу соотносительного расположения их в речи (сочетаемость, аранжировка и др.). В основу этого типа группировки положена дистрибуция, то есть совокупность всех возможных контекстов, где могут встретиться слова. Формализация семантических средств в синтагматике происходит через механизмы теорий вероятности и алгоритмов, а также статистико-вероятностного подхода.
Соотношение парадигматического и синтагматического подходов в семантике позволяет выявить некоторые их общие черты, семантические инварианты, а также элементарные семантические единицы (более мелкие и универсальные, чем слово) – семы. Последние представляют собой семантические признаки, которые в парадигматике являются признаком оппозиции, а в синтагматике – признаком сочетаемости.
Как сделать семантическую кластеризацию запросов?
Чтобы провести семантическую кластеризацию поисковых запросов, нужно:
- Собрать полное семантическое ядро.
- Удалить из него все дубли, мусор и минус-слова.
- Определить интент для каждого ключевого запроса.
- Выбрать методику формирования кластеров.
Собрать семантическое ядро можно с помощью сервиса Яндекс Wordstat, а также расширений для браузера типа WordStater. Затем выгрузить данные в Excel и подготовить их для дальнейшей кластеризации. Нужно стремиться к тому, чтобы при кластеризации главный поисковый запрос был определен максимально корректно.
Определяем поисковый интент
Поисковые интенты ключевых слов делятся на коммерческие (когда пользователь хочет приобрести товар или услугу) и информационные (когда он просто ищет информацию по какой-то теме). Даже коммерческие сайты могут успешно продвигаться по информационным запросам, создавая для них отдельные страницы с релевантным контентом.
Иногда одни и те же поисковые фразы могут подразумевать и коммерческий, и информационный интент одновременно. Их соотношение может меняться с течением времени или в зависимости от сезонных трендов
В таких случаях важно определить преобладающее намерение пользователя. Для этого проанализируйте маркеры коммерческих и информационных интентов в запросах, а также изучите текущую поисковую выдачу и тип сайтов в ТОПе
При кластеризации все поисковые запросы нужно распределить в соответствии с преобладающими интентами.
Выбираем подходящий метод
Существует несколько методик группировки семантического ядра в кластеры. Выбор подходящего способа зависит от конкретных задач проекта, его масштабов и объема собранной семантики. Зачастую для достижения максимально точных результатов используют комбинацию сразу нескольких методов кластеризации. Во время кластеризации эти ключевые запросы должны быть сгруппированы оптимальным образом.

Логический метод
При этом подходе SEO-специалист вручную анализирует список ключевых слов и определяет на основе своей экспертности, какие ключи близки по смыслу и должны быть сгруппированы в один кластер. Метод хорошо подходит для небольших сайтов, семантическое ядро которых включает до нескольких сотен ключей.
Сегментация по семантической схожести
Данный метод учитывает смысловое сходство ключевых формулировок по поисковым запросам. При этом родовые понятия, видовые уточняющие термины и даже отдельные слова могут восприниматься аудиторией как синонимы и быть отнесены в один смысловой кластер. Методика хороша для крупных ресурсов и реализуется с помощью сторонних онлайн-сервисов или десктопных программ на базе нейросетей.
Группировка по топам
При этом способе сегменты формируются на основе анализа семантики сайтов, которые уже находятся в ТОП-10 выдачи Яндекса и Google по нужному региону. Если какие-то ключевые фразы встречаются на продвигаемых страницах конкурентов с хорошими позициями чаще определенного количества раз, их объединяют в один кластер.









Алгоритм кластеризации семантического ядра по топам
Разделение семантики на группы с учетом текущей поисковой выдачи проводится тремя разными способами: мягким (Soft), жестким (Hard) и средним (Middle).
Soft-уровень
Это наименее строгий тип группировки, при котором второстепенные поисковые фразы могут даже не пересекаться друг с другом и с основным маркерным ключом кластера. Такой вариант можно использовать для небольших новых сайтов в тематиках с низкой конкуренцией. Нужно следить, чтобы при кластеризации главный поисковый запрос был определен верно.
Hard-уровень
Метод отбирает в кластер только максимально релевантные ключевые запросы, которые обязательно пересекаются как с маркерной фразой, так и между собой. В итоге мы получаем посадочную страницу, которая точно отвечает на конкретную потребность пользователя. Жесткую кластеризацию применяют для крупных сайтов в высококонкурентных нишах и для продвижения в особо сложных тематиках.
Middle-уровень
Это сбалансированный компромиссный вариант, при котором ключи должны пересекаться с маркером кластера, но не обязательно связаны между собой. Такой подход обычно используют для кластеризации семантики информационных сайтов, а также коммерческих ресурсов в нишах с невысокой конкуренцией.
Что такое интент и зачем его надо знать?
Интентом называют намерение или цель пользователя, которые он вкладывает в свой поисковый запрос. Понимание интентов помогает сгруппировать ключевые слова, отражающие схожие потребности и задачи аудитории. Поисковые системы стараются по интенту запроса понять, какую информацию ищет пользователь, чтобы предоставить ему максимально релевантную выдачу. Что такое кластеризация запросов и зачем она нужна? Знание интентов помогает SEO-специалисту создавать кластеры слов-ключевиков, которые соответствуют реальным потребностям посетителей. Затем на основе этих кластеров оптимизировать контент, чтобы он точно отвечал на вопросы пользователей и предоставлял им ценную информацию. Кластеризации все поисковые запросы должны быть распределены по кластерам в соответствии с интентами.

Для вас подарок! В свободном доступе до 31 октября
Получите подборку файлов
Для роста продаж с вашего сайта
Чек-лист по выбору SEO-подрядчика
5 шагов для быстрого ростаконверсии вашего сайта
Как проверить репутацию вашего бренда
Чек-лист по проверке рекламыв Яндекс-Директ

Получить документы
Уже скачали 1348 раз
Почему поисковые системы используют семантический поиск
Судя по перспективам поисковых систем, не трудно предположить, почему Google хочет расширить возможности коммуникации с миром: увеличить базу данных, сократить количество спама, глубже понимать намерения пользователей, использовать более естественный язык. Все это увеличивает возможность предоставления пользователям самого лучшего поискового опыта.
Мировой объем информации каждые два года удваивается. Большой объем данных давно стал нормальным для игроков онлайн-сферы. Какое значение это имеет для вас? Поисковые системы лучше работают с организованной, структурированной информацией, семантика которой соответствует данным.
Один из путей того, как семантический поиск помогает Google, заключается в идентификации и дисквалификации контента низкого качества. Методы вроде спиннинга текстов, начинения контента ключевыми словами легко распознаются системой из-за таких преимуществ, как скрытое семантическое индексирование (LSI), латентное размещение Дирихле (LDA) и статистическая мера TF-IDF. Благодаря использованию этих инструментов, вычисляется частота повторения слова и осуществляется соотнесение количества упоминаний с контекстом. Это значит, что поисковые системы имеют представление о статистических особенностях повторения слов в конкретном контексте и делают семантические корреляции, которые могут использоваться в войне против спама.
Используя семантику и субъективный поиск, поисковые системы получили возможность лучше понимать, что пользователи имеют в виду при наборе запроса.
Например, изображение ниже – это упрощенная иллюстрация того, как выглядит персонально ориентированный поиск. В него входят субъекты и предметы (люди, места, вещи, концепты, идеи), которые представлены в виде узлов и связаны отношениями – стрелками. Диаграмма показывает, как персонально ориентированный поиск использует разные объекты, в нашем случае персонажей мультфильма Симпсоны, чтобы дать более глубокий ответ на вопрос пользователя.
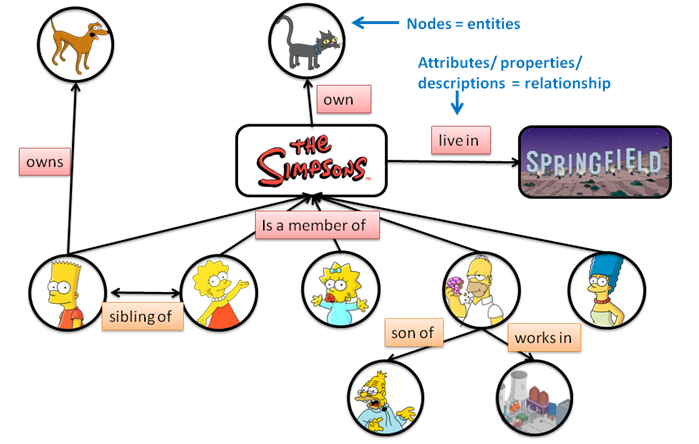
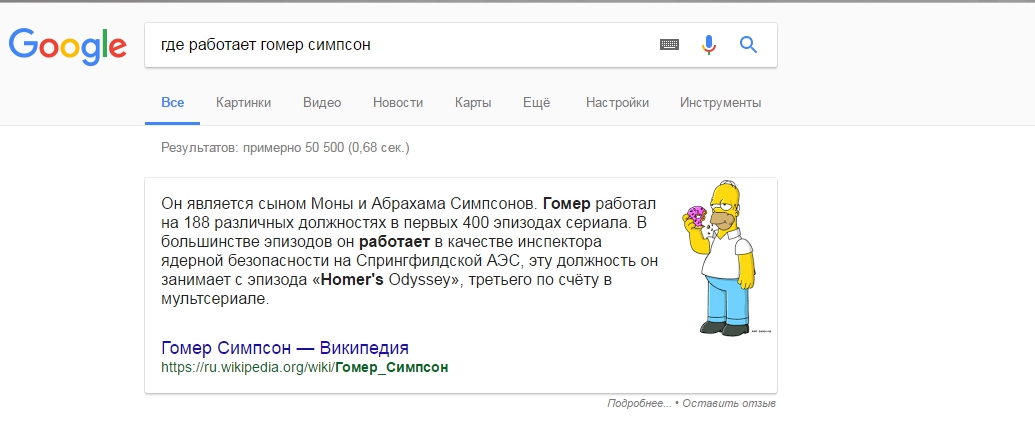
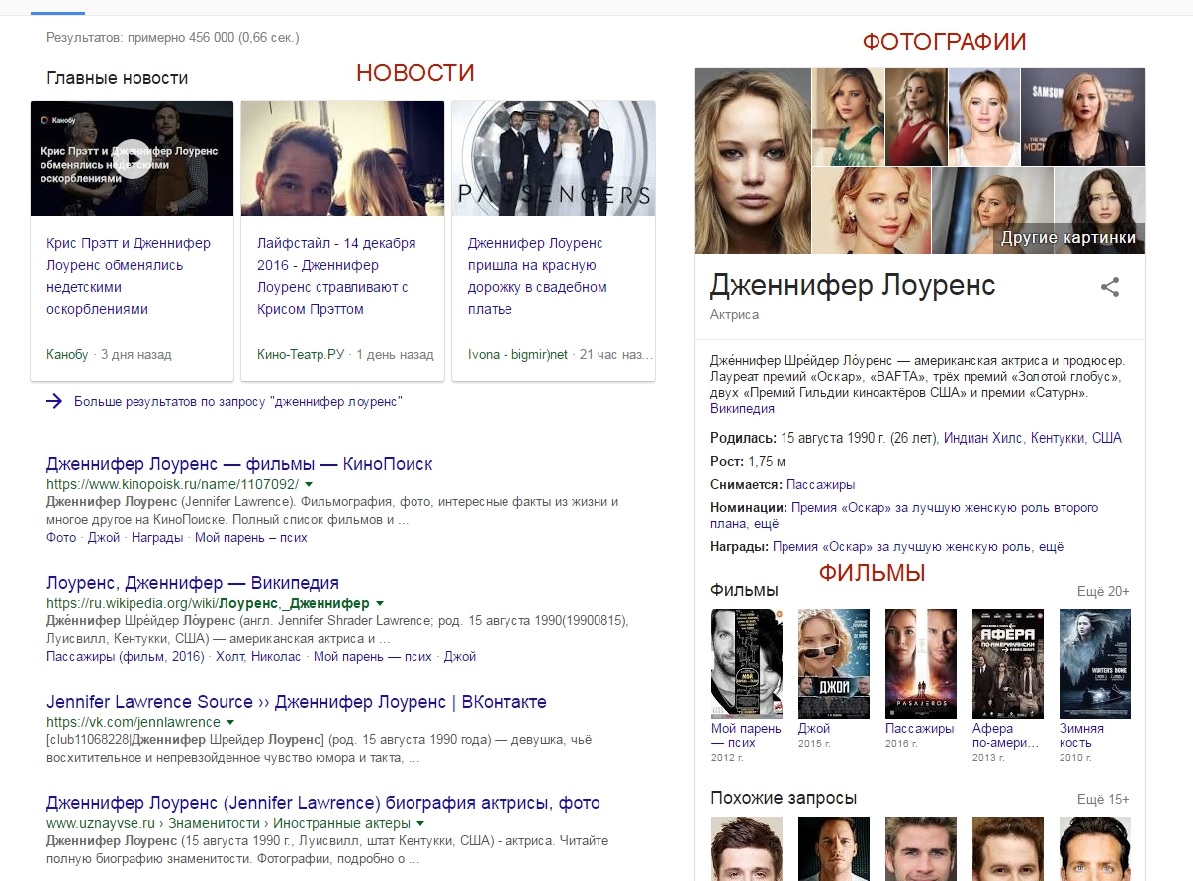
Google, как и другие поисковые системы, стал очень искусным в распознавании различных субъектов и формулировании ответов на вопросы. Поиск обеспечивает связь данных и становится сильнее.
Ответы на вопросы формируются через алгоритмы и выводятся, когда, например, кто-то ищет «кто танцует в видео chandelier». Google знает, что это Мэдди Зиглер.
Как видите, идея о том, что поисковик по ключам доберется до сути и с высокой степенью точности правильно ответит на вопрос, делает процесс получения информации более конструктивным для пользователей.