
Особенности порядка неубывания

Порядок неубывания представляет собой упорядоченный ряд элементов, где каждый следующий элемент больше предыдущего
Важно понимать, что в таком порядке элементы не могут повторяться, иначе он будет нарушен
Основная особенность порядка неубывания состоит в том, что он позволяет выполнять операции с элементами из заданного ряда, используя их упорядоченность.
Одной из основных преимуществ порядка неубывания является возможность эффективного поиска элементов в отсортированном ряду. Благодаря упорядоченности элементов, можно использовать такие алгоритмы поиска, как бинарный поиск, который имеет логарифмическую сложность. Это позволяет значительно сократить время поиска.
Примечание: время поиска в неотсортированном ряду может быть значительно больше, так как требуется просматривать все элементы по очереди.
Другой важной особенностью порядка неубывания является возможность быстрой вставки элементов. Если известно место, куда нужно вставить новый элемент, можно выполнить это действие за линейное время
Достаточно просто сдвинуть все элементы, расположенные после вставляемого, и вставить его на нужное место.
Примечание: в неотсортированном ряду для вставки элемента может потребоваться просмотреть все элементы до нужного места, что требует значительно больше времени.
Кроме того, порядок неубывания позволяет эффективно удалять элементы из ряда. Если известное место удаляемого элемента, его можно удалить за линейное время, сдвинув все элементы после него. Другие элементы при этом не изменят своего порядка.
Примечание: в неотсортированном ряду для удаления элемента также потребуется просмотреть все элементы, что является менее эффективным.
Таким образом, особенности порядка неубывания обеспечивают возможность эффективной работы с упорядоченным рядом элементов, что является важным для многих алгоритмов и задач.
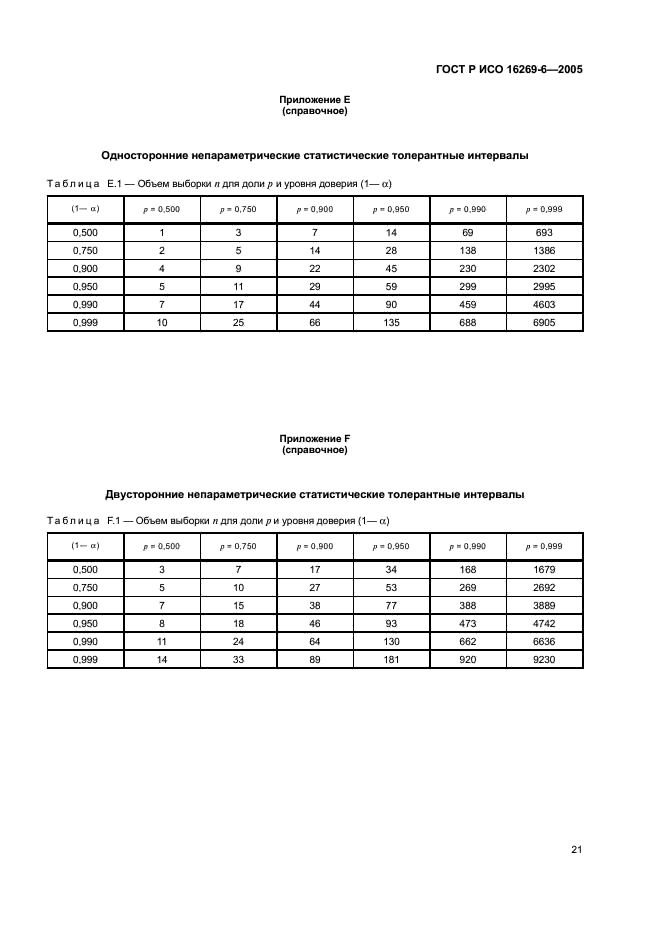
Приложение А(справочное)
Классический метод определения границ доверительных интервалов для медианы
Предположим, что выборка объема выбрана случайным образом из непрерывной генеральной совокупности. Тогда вероятность того, что точно выборочных значений будут менее медианы совокупности, описывается биномиальным распределением:
.
Это является также и вероятностью того, что точно выборочных значений будут более медианы совокупности.
Нижней и верхней границами двустороннего доверительного интервала, соответствующего доверительной вероятности (), являются достаточные статистики и соответственно. Значение величины должно удовлетворять следующим неравенствам:
; (А.1), (А.2)
то есть
; (А.3). (А.4)
При определении границ одностороннего доверительного интервала в уравнениях (А.1)-(А.4) необходимо заменить /2 на .
От сортировки вставками до сортировки слиянием
В алгоритме сортировки вставкой в каждый произвольный момент
начальная часть списка уже отсортирована.
Далее первый элемент из неотсортированной части добавляется в отсортированную часть списка.
Таким образом, мы n раз подряд производим слияние двух отсортированных списков:
одного длины 1, 2, и так далее до n-1, и второго — каждый раз длины 1.
Однако же мы знаем, что два списка длин n и m можно слить вместе в один отсортированный список
за время порядка n+m.
Если мы сначала разобьём элементы на пары, которые сольём в списки длины 2,
затем их сольём в списки длины 4, и так далее, то потратим как раз O(n log n) операций.
Упорядоченные списки и их структура
Упорядоченный список, также известный как нумерованный список, представляет собой список элементов, которые последовательно упорядочены по порядку их позиции. Каждый элемент списка имеет свой уникальный номер или метку, которая помогает идентифицировать его положение в списке.
Структура упорядоченного списка состоит из тега <ol> (ordered list), внутри которого располагаются элементы списка, представленные тегами <li> (list item). Каждый элемент списка обычно отображается с номером или маркером, который указывает на его местоположение в упорядоченном списке.
В отличие от упорядоченных списков, неупорядоченные списки (<ul>) не имеют нумерации или маркеров. Они представляют собой просто список элементов, расположенных в порядке их введения. Каждый элемент списка отображается с помощью маркера, обычно символа маленького кружка или точки.
Структура неупорядоченного списка состоит из тега <ul>, внутри которого располагаются элементы списка, представленные тегами <li>. Каждый элемент списка отображается с маркером, который указывает на его принадлежность к списку.
Также существуют и другие типы списков, такие как многоуровневые списки, где элементы списка могут иметь вложенные уровни, и они представляют собой иерархическую структуру.
Для создания многоуровневых списков используются вложенные теги <ul>, <ol> и <li>. Таким образом, элементы списка могут иметь вложенные списки внутри себя, что позволяет создавать более сложные структуры иерархий.
| Тег | Описание |
|---|---|
| <ol> | Тег для создания упорядоченного списка |
| <ul> | Тег для создания неупорядоченного списка |
| <li> | Тег для создания элемента списка |
Использование упорядоченных и неупорядоченных списков помогает упорядочить информацию и сделать ее более структурированной. Они широко используются в HTML-разметке для представления элементов документа, таких как меню, инструкции или перечни.
Что делать, если данные не помещаются в оперативную память
Если данных очень много, то они не поместятся в оперативную память,
и стандартные методы сортировки применить будет невозможно.
Отличительной особенностью внешних носителей данных является скорость доступа.
Скажем, время на получение информации из оперативной памяти в современном компьютере составляет порядка 50нс,
а из жёсткого диска — порядка 5мс. Это в сто раз больше.
Скорость последовательного чтения с жёсткого диска составляет примерно 200МБ/с, в то время как
скорость чтения из оперативной памяти имеет порядок 20ГБ/с, снова в 100 раз быстрее.
При непоследовательном доступе к жёсткому диску задержки увеличиваются, скорость сильно падает.
Сортировки данных, хранящихся на периферийных устройствах (например, жёстких дисках) и не вмещающихся в оперативную память, называются внешними.
Для того, чтобы внешняя сортировка была быстрой, необходимо минимизировать количество доступов к периферийных устройствам,
при этом максимально использовать только длительные последовательные доступы.
Большинство способов внешних сортировок так или иначе связана с сортировкой слиянием.
Например, можно взять исходную последовательность и разбить на серии, которые помещаются в оперативную память.
Каждую серию отсортировать стандартным образом и записать на жёсткий диск.
После этого нужно будет производить слияния до тех пор, пока весь массив не будет отсортирован.
Предположим, что оперативная память вмещает P элементов, а нам нужно отсортировать P×2k элементов.
Тогда мы первый раз прочитаем и запишем каждый элемент при подготовке серий.
В результате P×2k чтений-записей получатся серии длины P.
После первого слияния мы получим серии длины P×21, затем P×22 и так далее.
В результате потребуется (k+1) полных прочтений и записей данных на диск.
Для увеличения скорости необходимо уменьшить количество чтений-записей.
И здесь можно двигаться в двух направлениях: увеличивать длину отсортированных серий,
которые получаются при первом проходе, и уменьшать количество чтений-записей при последующих слияниях.
Существует красивая идея, которая позволяет после первого прохода получить отсортированные серии длиной не P,
а в среднем 2P. Если же при этом данные будут частично отсортированы, то длины серий будут ещё больше.
Об этой идее есть задача ниже.
Теперь представим себе, что мы можем выполнять эффективное слияние не 2-х массивов, а сразу 4-х.
Тогда после первого слияния мы получим серии длиной сразу P×22, а итоговое
количество чтений-записей данных станет почти в два раза меньше!
Порядок неубывания в реальной жизни
Понимание и умение применять понятие «порядок неубывания» в реальной жизни имеет множество применений. В одном из примеров мы можем рассмотреть использование этого понятия в экономической сфере.
Порядок неубывания также может применяться при анализе данных. Например, при исследовании изменения температуры в какой-либо области, можно сравнить изменения каждого года и увидеть, как меняется показатель температуры от года к году.
Также в медицинском и фармацевтическом секторе порядок неубывания может использоваться для сравнения эффективности лекарственных препаратов. Здесь каждый препарат можно упорядочить по уровню эффективности, что позволит выбрать оптимальный вариант лечения для каждого конкретного случая.
В целом, понимание концепта «порядок неубывания» в математике и его применение в реальной жизни помогает в принятии эффективных решений в различных областях деятельности и в повседневной жизни.
Объясните пожалуйста как это делать
Анализируем задание.1. Сумма кубов старшего и младшего разрядов и куб суммы старшего и младшего разрядов. Смотрим в пример, нам дано число 51. Сумма кубов это 5^3 + 1^3 = 125 + 1 = 126. Куб суммы это (5+1)^3 = 6^3 = 216. Все верно.2. В порядке невозрастания — это значит, что в порядке убывания, то есть сначала мы записываем большее число (в примере 216), а потом меньшее (126). Получается число 216126.
Теперь анализируем данные нам числа. 10 у нас получиться не может, т.к. 1 и 0 получиться в результате вычислений (куб суммы и сумма кубов) не могут. 82. В результате вычислений должно получиться 8 и 2. Замечаем, что 8 — это 2^3, то есть куб суммы может быть равен 2. Давайте действительно предположим, что куб суммы может быть равен 2. Сразу исключается вариант (0+2)^3, т.к. число 02, то есть 2, не двузначное. Исключается и вариант (2+0)^3, т.к сумма кубов числа 20 равна 2^3 + 0^3 = 8, а куб суммы равен (2+0)^3 = 2^3 = 8. Получается число 88, а не 82. Рассматриваем число 11. (1+1)^3 = 2^3 = 8. 1^3 + 1^3 = 1+1 = 2. Записываем в порядке убывания и получаем число 82. 3. 28 получиться не может, т.к. 2 и 8 записаны в порядке возрастания, а 28 и 0 невозможно, т.к. в результате вычислений такие числа не получатся.4. 927. Сразу понятно, что числа 9 и 27 не могут получиться в результате вычислений (они расположены в порядке возрастания). Тогда берем 92 и 7. Нет таких чисел, которые в кубе давали бы 92 и 7, поэтому это число не может получиться в результате преобразований. (Если бы хотя бы одно число являлось кубом, тогда можно было бы поразмыслить)5. 6415. Можем взять числа 64 и 15. Расположены в порядке неубывания. 64 — это куб 4, значит, куб суммы должен быть равен 64. Замечаем, что мы в расчет взять можем только числа 4, 3, 2 и 1, кубы которых равны 64, 27, 8 и 1 соответственно, но не получится никак сделать из них 15, поэтому пара 64 и 15 не подходит. 641 и 5 тоже не подходит, так как ни одного числа с такими кубами нет.6. 216126 подходит, см пример в условии7. 512512. Ну сразу понятно, что 512 — это куб 8. Работаем Сумма кубов должна быть равна 512 и куб суммы тоже должен быть равен 512. Нет таких кубов, которые давали бы нам 512 в сумме, но мы видим, что числа одинаковые, потому можем сделать одну цифру в числе равной 0. 80 — идеальное число. (8+0)^3 = 8^3 = 512. 8^3 + 0^3 = 8^3 = 512. Получается 512512.8. 62550. 6 и 2550; 62 и 550 — не подходят, т.к. расположены в порядке возрастания. Берем 625 и 50. Нет куба ни 625, ни 6255, ни 50, ни сумма никаких кубов не сможет дать нам такие числа. Не подходит.Итог: могут получиться числа: 82, 216126, 512512Ответ: 3 Мой мозг..
Сложность сортировки пузырьком
В алгоритме сортировки пузырьком фигурируют две различных
нетривиальных операции: условное ветвление по результатам сравнения и
обмен двух элементов массива местами.
Будем считать, что каждая из этих операций занимает единицу времени,
а всё остальное (например, обслуживание счётчиков циклов) бесплатно.
Тогда для массива длины \(N\) алгоритм занимает
\
единиц времени. Заметим, что, начиная с \(N=4\), выполнено
неравенство
\
Также всегда выполнено неравенство
\
То есть, начиная с некоторого \(N\), время работы алгоритма
заключено между значениями выражений, пропорциональных \(N^2\).
В такой ситуации говорят, что \(N^2\) является
асимптотической сложностью рассматриваемого алгоритма.




В общем случае, если \( T(N) \) — (максимально возможное)
время работы алгоритма на наборе данных размера \( N \),
а \(f\) — некоторая функция натурального аргумента, то говорят, что:
- алгоритм обладает верхней асимптотической сложностью \( f(N) \), если
существует такое положительное число \( \alpha \), что, начиная с некоторого
\(N\), выполнено неравенство \( T(N) \leqslant \alpha f(N) \) - алгоритм обладает нижней асимптотической сложностью \( f(N) \), если
существует такое положительное число \( \alpha \), что, начиная с некоторого
\(N\), выполнено неравенство \( T(N) \geqslant \alpha f(N) \) - алгоритм обладает асимптотической сложностью \( f(N) \), если
он обладает нижней и верхней асимптотическими сложностями \( f(N) \)
Например, про сортировку пузырьком можно сказать, что:
- она обладает верхней асимптотической сложностью \( N^2 \)
- она обладает верхней асимптотической сложностью \( 1000N^2 \)
- она обладает верхней асимптотической сложностью \( N^{1000} \)
- она обладает нижней асимптотической сложностью \( N^2 \)
- она обладает нижней асимптотической сложностью \( 1000N^2 \)
- она обладает нижней асимптотической сложностью \( N \)
- она обладает асимптотической сложностью \( N^2 \)
Часто можно встретить обозначение \(O( f(N) )\) для множества
алгоритмов, обладающих асимптотической сложностью \( f(N) \).
Иногда буква \(O\) относится только к верхней асимптотической сложности:
в таких ситуациях для нижней асимптотической сложности используется
буква \( \Omega \) (омега большая), а для (просто) асимптотической
сложности — буква \( \Theta \) (тета большая).
Преобразование множеств
Иногда возникает необходимость представления уже готовой последовательности значений в качестве совсем другого типа данных. Возможности языка позволяют конвертировать любое множество в строку, словарь или список при помощи стандартных функций.
Строка
Для преобразования множества в строку используется конкатенация текстовых значений, которую обеспечивает функция join. В этом случае ее аргументом является набор данных в виде нескольких строк. Запятая в кавычках выступает в качестве символа, разделяющего значения. Метод type возвращает тип данных объекта в конце приведенного кода.
a = {'set', 'str', 'dict', 'list'}
b = ','.join(a)
print(b)
print(type(b))
set,dict,list,str
<class 'str'>
Словарь
Чтобы получить из множества словарь, следует передать функции dict набор из нескольких пар значений, в каждом из которых будет находиться ключ. Метод print демонстрирует на экране содержимое полученного объекта, а type отображает его тип.
a = {('a', 2), ('b', 4)}
b = dict(a)
print(b)
print(type(b))
{'b': 4, 'a': 2}
<class 'dict'>
Следует отметить, что каждый элемент для такого преобразования — кортеж состоящий из двух значений:
- ключ будущего словаря;
- значение, соответствующее ключу.
Список
По аналогии с предыдущими преобразованиями можно получить список неких объектов. На этот раз используется метод list, получающий в качестве аргумента множество a. На выходе функции print отображаются уникальные значения для изначального набора чисел.
a = {1, 2, 0, 1, 3, 2}
b = list(a)
print(b)
print(type(b))
<class 'list'>
От сортировки пузырьком к быстрой сортировке Хоара и поиску медианы
быстрой сортировкойсортировкой Хоараquicksort
В сортировке пузырьком мы переставляем элемент только на соседнюю позицию, «всплывая» его, насколько это возможно.
При этом после «всплытия» мы ещё много раз будем выполнять сравнения с этим элементом.
В быстрой сортировке мы берём элемент и максимально быстро «топим» элементы, меньшие его, и «всплываем» элементы, большие.
Тем самым элемент оказывается на необходимой для него в отсортированном массиве позиции.
После этого рекурсивно сортируем всё меньшее и отдельно большее, необходимости сравнивать с данным элементом при этом уже никогда не будет.
Точнее, основа алгоритма — рекурсивная функция, принимающая на вход список, а также позиции от и до которой необходимо отсортировать список.
При сортировке всего списка используются значения по умолчанию — сортировать от начала и до конца.
def quicksort(A, begin=0, end=-1): pass
опорный элемент
Этот алгоритм обладает достаточно забавным свойством: если мы каждый раз будем выпирать опорный элемент очень неудачно (например строго минимальным или максимальным),
то время его работы будет порядка n+(n-1)+…+1, то есть O(n2).
Однако обычно такого не происходит, и данный алгоритм часто оказывается быстрее некоторых других, гарантирующих работу за n log n.
Процедура разделения массива оказывается полезной ещё и для нахождения медианы (элемента, который в отсортированном массиве стоит посередине),
и более обще: k-й порядковой статистики (элемента, который в отсортированном массиве идёт k-ым).
Если наш массив имеет длину n, то статистики с номерами 0.05n, 0.25n, 0.5n, 0.75n и 0.95n могут многое рассказать о распределении чисел в массиве.
Например, если взять зарплаты в России в 2007 году, то эти статистики получатся примерно такими:
2000, 5000, 9000, 15000, 35000.
Заметим, что при таком распределении средняя заработная плата может быть сколь угодно велика (в 2007 она была примерно 15000).
Хотя 75% населения получали зарплату не большую 15000р, и более половины населения — вообще менее 10000р.
Идея поиска k-й порядковой статистики в следующем.
Выберем случайный опорный элемент и переупорядочим массив так, чтобы сначала шли элементы, строго меньшие опорного, затем равные опорному,
и наконец строго большие опорного.
Заметим, что сделать такую разбивку чуть сложнее, чем более простую, необходимую для сортировки Хоара.
Пусть элементов, строго меньших опорного S<, равных опорному — S=.
Тогда сравнивая число k с S< и S<+S= легко понять,
в какой части массива нужно искать ответ.
в порядке неубывания
Русско-английский математический словарь . 2013 .
Смотреть что такое «в порядке неубывания» в других словарях:
Закон неубывания энтропии — Закон неубывания энтропии: «В изолированной системе энтропия не уменьшается». Если в некоторый момент времени замкнутая система находится в неравновесном макроскопическом состоянии, то в последующие моменты времени наиболее вероятным следствием… … Википедия
Двоичное дерево поиска — Тип Дерево Временная сложность в О символике В среднем В худшем случае Расход памяти O(n) O(n) Поиск O(h) O(n) Вставка O(h) O(n) Удаление O(h) O(n) где h высота дерева … Википедия
Printf — printf обобщённое название семейства функций или методов стандартных или широкоизвестных коммерческих библиотек, или встроенных операторов некоторых языков программирования, используемых для форматного вывода вывода в различные потоки … Википедия
Snprintf — printf обобщённое название семейства функций или методов стандартных или широкоизвестных коммерческих библиотек, или встроенных операторов некоторых языков программирования, используемых для форматного вывода вывода в различные потоки значений… … Википедия
Sprintf — printf обобщённое название семейства функций или методов стандартных или широкоизвестных коммерческих библиотек, или встроенных операторов некоторых языков программирования, используемых для форматного вывода вывода в различные потоки значений… … Википедия
Swprintf — printf обобщённое название семейства функций или методов стандартных или широкоизвестных коммерческих библиотек, или встроенных операторов некоторых языков программирования, используемых для форматного вывода вывода в различные потоки значений… … Википедия
Vasprintf — printf обобщённое название семейства функций или методов стандартных или широкоизвестных коммерческих библиотек, или встроенных операторов некоторых языков программирования, используемых для форматного вывода вывода в различные потоки значений… … Википедия
Vfprintf — printf обобщённое название семейства функций или методов стандартных или широкоизвестных коммерческих библиотек, или встроенных операторов некоторых языков программирования, используемых для форматного вывода вывода в различные потоки значений… … Википедия
Vsprintf — printf обобщённое название семейства функций или методов стандартных или широкоизвестных коммерческих библиотек, или встроенных операторов некоторых языков программирования, используемых для форматного вывода вывода в различные потоки значений… … Википедия
Vprintf — printf обобщённое название семейства функций или методов стандартных или широкоизвестных коммерческих библиотек, или встроенных операторов некоторых языков программирования, используемых для форматного вывода вывода в различные потоки значений… … Википедия
Vsnprintf — printf обобщённое название семейства функций или методов стандартных или широкоизвестных коммерческих библиотек, или встроенных операторов некоторых языков программирования, используемых для форматного вывода вывода в различные потоки значений… … Википедия
Источник
Последовательный поиск
Если исходный массив не упорядочен, то единственно разумным способом является последовательный перебор всех элементов массива и сравнение их с заданным значением.
Классический алгоритм поиска элемента q в массиве а:
1 шаг: установить начальный индекс равный 1 (j=1)
2 шаг: проверить условие q=a, если оно выполняется, то сообщить, что искомое значение находится в массиве на j-о м месте и прервать работу. В противном случае продолжить работу;
3 шаг: увеличить индекс на 1;
4 шаг: проверить условие j<n+1, если выполняется, то вернуться к шагу 2, в противном случае выдать сообщение, что данное значение q в массиве не содержится
int ssearch (int q, int a, int n)
{ int j;
for (j=0; j<n; j++)
if (q= =a) return j;
return -1;
}
От сортировки выбором к пирамидальной сортировке
Для определённости будем сортировать массив по возрастанию. (Точнее, по неубыванию, так как в массиве могут быть совпадающие элементы).
Основная схема сортировки выбором сохраняется. Массив разделен на
две части, одна из которых (правая) уже отсортирована, причем любой элемент отсортированной части не меньше любого элемента неотсортированной:
пока размер неотсортированной части > 1 выполнять | найти максимальный элемент | переставить его в конец отсортированной части конец
В простой сортировке выбором мы за $k-1$ сравнение (где $k$ – длина неотсортированной части) всего лишь находили максимальный (минимальный) элемент. При этом мы часто получали информацию про относительные величины некоторых пар элементов, но «забывали» её.
В пирамидальной сортировке эта информация будет сохраняться.
Другими словами: неотсортированная часть будет не совсем беспорядочной — она будет иметь внутреннюю структуру, которая позволит каждый
раз быстро выбирать максимальный элемент.
Для его реализации этого «сохранения» понадобится структура данных, называемая двоичной (бинарной) кучей или
пирамидой (По-английски эта структура данных называется $heap$, дословный перевод – куча, но
термин $пирамида$, который тоже иногда используется, лучше соответствует сути дела. Рассматриваемый здесь алгоритм сортировки называют сортировкой с помощью
кучи, пирамидальной сортировкой или, реже, сортировкой деревом.).
Одновременно с этим окажется удобно изучить также основанную на куче приоритетную очередь.
Как быстро нужно уметь извлекать из кучи максимальный элемент?
Чтобы сложность сортировки была $O(n$ log $n)$, достаточно, чтобы время выбора было $O($log $n)$).
Основная идея кучи состоит в том, что мы рассматриваем массив как представление двоичного дерева и вводим некоторый
порядок на узлах этого дерева.
Итак, если мы реализуем такую структуру, то алгоритм сортировки приобретёт следующий вид:
Сортировка слиянием
Используется метод “разделяй и властвуй”: массив разбивается пополам, каждая из частей рекурсивно сортируется, затем отсортированные части объединяются.
Рекурсия очевидно имеет конечную глубину, т.к. массив 1 элемента тривиально отсортирован.
Оценим сложность вычислений. Пусть сортировка массива размера \(n\) имеет сложность \(t(n)\). На каждом уровне рекурсии тогда требуется \(2t(n/2)+q(n),\) где \(q(n)\) – сложность объединения . \(q(n) = \mathcal O(n) = c\cdot n\). Тогда имеем

\[t(n) = 2t(n/2)+c\cdot n\] \
Тогда
\[t(n) = 2(2t(n/2^2)+c\cdot n/2)+c\cdot n = 2^2 t(n/2^2)+2c\cdot n\] \[t(n) = 2^2 (2t(n/2^3)+c\cdot n/4)+2c\cdot n = 2^3t(n/2^3)+3c\cdot n\] \ \
Можно показать (сделаем это позже), что сортировка, основанная на бинарном сравнении, не может иметь сложность ниже \(\mathcal O(n\log n).\)
Операции над множествами
Помимо различных манипуляций с элементами множеств, существуют еще и операции над ними, позволяющие одной строчкой кода выполнять сложные преобразования.
Рассмотрим операции с множествами доступные в Python 3.
Объединение
Чтобы объединить все элементы двух разных множеств, стоит воспользоваться методом union на одном из объектов. Следующий пример демонстрирует работу данной функции, где создается последовательность чисел под именем c.
a = {0, 1, 2, 3}
b = {4, 3, 2, 1}
c = a.union(b)
print(c)
{0, 1, 2, 3, 4}
Добавление
Чтобы добавить все элементы из одного множества к другому, необходимо вызывать метод update на первом объекте. Таким образом можно перенести уникальные данные из одного набора чисел в другой, как это показано в следующем примере.
a = {0, 1, 2, 3}
b = {4, 3, 2, 1}
a.update(b)
print(a)
{0, 1, 2, 3, 4}
Пересечение
Чтобы найти общие элементы для двух разных множеств, следует применить функцию intersection, принимающую в качестве аргумента один из наборов данных. Код, приведенный ниже, создает новую последовательность чисел из пересечения двух множеств в Python 3.
a = {0, 1, 2, 3}
b = {4, 3, 2, 1}
c = a.intersection(b)
print(c)
{1, 2, 3}
Разность
Чтобы вычислить разность для двух разных множеств, необходимо воспользоваться методом difference. Функция позволяет найти элементы, уникальные для второго набора данных, которых в нем нет. Следующий код демонстрирует эту операцию.
a = {0, 1, 2, 3}
b = {4, 3, 2, 1}
c = a.difference(b)
print(c)
{0}
Двоичная куча (пирамида)
Следующая картинка показывает, как можно отобразить элементы массива A
на вершины двоичного дерева:
A
/ \
A A
/ \ / \
A A A A
/
A
почти полнымi(i-1)//22i+12i+2
Высотой дерева будем называть число уровней в дереве (или, что то же самое, длину пути от корня до самого дальнего листа плюс один).
Так, для дерева на рисунке длина пути от корня до листа A равна 3, а высота равна 4.
Полезно установить связь между высотой h и числом вершин дерева s.
Упражнение. Сколько вершин может иметь почти полное двоичное дерево высоты h?
Выразите высоту почти полного двоичного дерева через число вершин.
Чтобы быстро искать максимум в этом дереве, расположим элементы массива так, чтобы значение любого элемента было не меньше значений всех его
потомков (если они существуют).
Для этого достаточно, чтобы для каждого i выполнялись два неравенства:
A ≥ A (если 2i+1 ≤ s), и A ≥ A (если 2i + 2 ≤ s).
Вообще говоря, часто будет удобно, чтобы этому правилу подчинялись не
обязательно все элементы массива, а лишь элементы его некоторого начального участка.
Этот участок и будем называть кучей. Будем обозначать размер всего массива n, а размер кучи – s.
Размер кучи может меняться от до n включительно.
Итак, двоичной максимальной кучей будем называть некоторое начало
массива , (0 ≤ s ≤ n) если каждый его элемент обладает основным
свойством максимальной кучи: его значение не меньше значений всех его
потомков.